# 1. 前言
# 1.1 PDF文档解析的困难
PDF文件并非传统意义上的数据格式,而更像是一系列打印指令的集合。这些指令告诉PDF阅读器或打印机如何在屏幕或纸张上展示文字、图像和其他元素。与HTML或DOCX等结构化文档不同,PDF文件不直接包含元素的逻辑结构,这使得从PDF中提取信息变得尤为困难。主要挑战包括:
- 页面布局的复杂性:PDF文档的布局可以非常多样,包括单栏、双栏、多列等,这增加了提取内容的难度。
- 文本提取的不准确性:由于PDF文件中的文本可能以图像形式嵌入,传统的文本提取方法可能无法准确获取所有内容。
- 图像和表格的识别:图像和表格的准确识别与解析是PDF解析中的另一大难题,特别是当它们与文本内容交织在一起时。
# 1.2 PDF文档解析的方法
# 1.2.1 基于规则的方法
基于规则的方法通过预定义的规则来确定PDF文档中每个部分的样式和内容。这种方法简单直接,但通用性不强,因为PDF的类型和布局多种多样,难以用有限的规则覆盖所有情况。
# 1.2.2 基于深度学习模型的方法
基于深度学习模型的方法利用神经网络来识别和解析PDF文档中的内容。这种方法通常结合了目标检测和OCR技术,能够更准确地识别文档中的文本、图像和表格。
- 优势:能够处理复杂的页面布局,保留文档的结构信息。
- 局限性:对象检测和OCR阶段可能比较耗时,且对计算资源的要求较高。
# 1.2.3 基于多模态大模型的方法
基于多模态大模型的方法利用大型预训练模型直接从PDF文档中提取复杂结构或关键信息。这种方法结合了文本、图像等多种模态的信息,能够更全面地理解文档内容。
- 优势:能够提取或总结关键信息,适用于需要深度理解和分析的场景。
- 局限性:需要将PDF处理成图像,将其发送给多模态大模型进行处理,对计算资源的要求较高。
# 1.3 文档解析工具对比
综合来看,基于深度学习模型的方法 > 基于多模态大模型的方法 > 基于规则提取的方法
- MinerU是目前综合来看解析效果最好的,它可以识别公式,并且其表格解析和布局检测也更好。
- DeepDoc、Docling、MarkitDown这些文档解析工具各有千秋,可以根据实际文档情况结合使用。
- Agentic Doc这个库的解析效果看着也挺不错的,但它没有开源,需要买它的API-KEY才能去用。
- ZeroX-OCR这个基于多模态大模型的工具就不用去试了,效果也不咋地,不知道怎么刷的高Star。
| 工具 | RAGFlow | Docling | PDF-Extract-Kit | MinerU |
|---|---|---|---|---|
| 特色 | 强大的布局、表格、图像、公式识别 | 高效的多格式转换,尤其适用于Markdown输出,但不支持图片提取 | 强大的布局和公式识别,适用于学术类PDF文档,具有较强鲁棒性 | 提供多种格式的输出、OCR支持、多平台支持,适用于各种类型的PDF文档 |
| 支持的文件格式 | PDF、DOCX、图片、HTML | PDF、DOCX、PPTX、图片、HTML | ||
| 输出格式 | JSON | Markdown、JSON | Markdown、JSON、HTML、LaTeX公式、中间格式 | Markdown、JSON、HTML、LaTeX公式、中间格式 |
| 输出的文本顺序 | 输出顺序可能不总是理想(尤其复杂布局时) | 输出顺序良好,基本没有遗漏。对于有明显样式的docx文档可以实现标题分层级输出 | 输出文本顺序良好,但布局识别后的文本提取效果一般 | 输出符合人类阅读顺序,适应单栏、多栏及复杂排版 |
| 局限性 | 复杂布局时文本遗漏,图片识别不准确 | 不支持提取图片、图注不完整,PDF层级提取不明显 | 布局识别后的文本提取效果不好 | 对双栏中文文本提取效果差,标题无层级,图注提取差 |
| 布局识别 | 支持布局识别,包括标题、文本、表格、图片等 | 支持 | 使用 LayoutLMv3 进行布局检测(图像、表格、标题、文本等) | 支持布局识别,包括标题、段落、列表、表格、图像等 |
| 公式识别 | 无 | 无 | 使用 YOLOv8 和 UniMERNet 进行公式检测和识别 | 自动识别并转换公式为LaTeX格式 |
| OCR 支持 | 支持多种语言和字体,处理复杂文档布局和图像质量 | 支持 | 使用 PaddleOCR 进行文本识别 | 支持OCR(84种语言),检测和识别扫描版PDF与乱码PDF |
| 表格提取 | 提取为HTML格式 | 提取为Markdown格式 | 准确提取表格内容 | 自动将表格提取为图片 |
| 图片提取 | 支持提取配图,但图像识别准确性较差且存在遗漏 | 不支持提取图片,仅提取图注 | 支持图像提取,并对图像进行区域检测 | 支持图像提取和图片描述,图注位于图片下方提取效果较好 |
| 页面元素 | 支持页头、页尾、参考引用、公式等 | 不支持提取页头、页尾等 | 支持页面元素的布局和公式识别 | 删除页眉、页脚、页码等元素,确保语义连贯 |
| 支持平台 | Linux、MacOS、Windows | Linux、MacOS、Windows | Linux、MacOS、Windows | 支持Windows、Linux、Mac平台 |
| 扩展性 | 无 | 无 | 可以与PaddleOCR等结合使用 | 支持OCR、图片描述等多种功能,可以扩展 |
# 2. MinerU文档解析
MinerU 是一个基于 PDF-Extract-Kit 构建的文档解析库,主要在工程层面进行了整合,大量复用了 PDF-Extract-Kit 的代码作为核心功能实现。
# 2.1 PDF-Extract-Kit内容提取
# 2.1.1 PDF-Extract-Kit简介
PDF-Extract-Kit 项目结合多样性PDF文档标注,训练了鲁棒的布局检测和公式检测模型。在论文、教材、研报、财报等多样性的PDF文档上,都能得到准确的提取结果,对于扫描模糊、水印等情况也有较高鲁棒性。
项目将PDF内容提取工作拆解为以下任务:
- 布局检测:使用 LayoutLMv3 (opens new window) 模型进行区域检测,如图像、表格、标题、文本等;
- 公式检测:使用 YOLOv8 (opens new window) 检测公式,包含行内公式和行间公式;
- 公式识别:使用 UniMERNet (opens new window) 进行公式识别;
- 光学字符识别:使用 PaddleOCR (opens new window) 进行文本识别;

# 2.1.2 PDF-Extract-Kit输出格式
PDF-Extract-Kit 输出格式
{
"layout_dets": [ # 页面上的元素
{
"category_id": 0, # 类别ID, 范围0~9, 13~15
"poly": [
136.0, # 坐标采用图像格式,需要转换回PDF坐标,顺序为左上、右上、右下、左下的x,y坐标
781.0,
340.0,
781.0,
340.0,
806.0,
136.0,
806.0
],
"score": 0.69, # 置信度分数
"latex": '' # 公式识别结果,仅类别13, 14有内容,其他为空,类别15为OCR结果,此键将被替换为文本
},
...
],
"page_info": { # 页面信息:提取边框时的分辨率大小,如果涉及缩放,可基于此信息进行对齐
"page_no": 0, # 页面编号
"height": 1684, # 页面高度
"width": 1200 # 页面宽度
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
包含的类型 category_id 如下:
{
0: 'title', # 标题
1: 'plain text', # 纯文本
2: 'abandon', # 包括页眉、页脚、页码和页面注释
3: 'figure', # 图像
4: 'figure_caption', # 图像标题
5: 'table', # 表格
6: 'table_caption', # 表格标题
7: 'table_footnote', # 表格脚注
8: 'isolate_formula', # 显示公式(这是一种布局显示公式,优先级低于14)
9: 'formula_caption', # 显示公式标签
13: 'inline_formula', # 行内公式
14: 'isolated_formula', # 显示公式
15: 'ocr_text' # OCR结果
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.1.3 PDF-Extract-Kit提取效果
项目训练了鲁棒的布局检测和公式检测模型,在论文、教材、研报、财报等PDF文档上,都能得到准确的提取结果。对于扫描模糊、水印等情况也有较高鲁棒性。

# 2.2 PDF-Extract-Kit使用实例
实验环境:Macbook Pro 2021,M1 Pro芯片,16G内存,macOS Sonoma 14.5系统,Python3.10环境
注:本项目适用于 Linux、MacOS、Windows 系统,其中 Linux 的安装教程即为官方主 README 里的,而 MacOS、Windows 里有单独的教程。
# 2.2.1 拉取代码并安装依赖
Step1:准备Conda环境
$ conda create -n pdf_extract_kit_env python=3.10
$ conda activate pdf_extract_kit_env
2
Step2:拉取代码安装依赖
$ git clone https://github.com/opendatalab/PDF-Extract-Kit.git
$ cd PDF-Extract-Kit
$ pip3 install unimernet==0.1.0
$ pip3 install -r requirements+cpu.txt
// 坑1:安装detectron2
$ pip3 install https://github.com/opendatalab/PDF-Extract-Kit/raw/main/assets/whl/detectron2-0.6-cp310-cp310-macosx_11_0_arm64.whl
// 坑2:安装freetype与imagemagick
$ brew install freetype imagemagick
$ open ~/.zshrc
export DYLD_LIBRARY_PATH="/opt/homebrew/lib:$DYLD_LIBRARY_PATH"
$ source ~/.zshrc
$ echo $DYLD_LIBRARY_PATH
2
3
4
5
6
7
8
9
10
11
12
13
14
注意事项:
- 对于detectron2,请参照 https://github.com/facebookresearch/detectron2/issues/5114 (opens new window) 自行编译,或者使用 PDF-Extract-Kit 项目作者编译的 wheel。
- 对于freetype与imagemagick,需要使用brew命令去安装,然后安装之后需要配置环境变量才能够生效。
# 2.2.2 下载模型并修改配置
Step1:下载模型文件
$ pip3 install modelscope
download_models.py
# -*- coding: utf-8 -*-
import os
import shutil
from modelscope import snapshot_download
# 模型仓库的标识
model_id = "wanderkid/PDF-Extract-Kit"
# 下载模型到临时目录
temp_dir = "./temp_models"
model_dir = snapshot_download(model_id=model_id, cache_dir=temp_dir)
# 目标目录
target_dir = "./models"
# 确保目标目录存在
if not os.path.exists(target_dir):
os.makedirs(target_dir)
# 移动文件
source_path = os.path.join(temp_dir, 'wanderkid', 'PDF-Extract-Kit', 'models')
for item in os.listdir(source_path):
s = os.path.join(source_path, item)
d = os.path.join(target_dir, item)
if os.path.isdir(s):
shutil.move(s, d)
else:
shutil.copy(s, d)
# 清理临时目录
shutil.rmtree(temp_dir)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
模型文件的文件结构:
./
├── Layout
│ ├── config.json
│ └── model_final.pth
├── MFD
│ └── weights.pt
├── MFR
│ └── UniMERNet
│ ├── config.json
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ ├── README.md
│ ├── tokenizer_config.json
│ └── tokenizer.json
│── TabRec
│ └─StructEqTable
│ ├── config.json
│ ├── generation_config.json
│ ├── model.safetensors
│ ├── preprocessor_config.json
│ ├── special_tokens_map.json
│ ├── spiece.model
│ ├── tokenizer.json
│ └── tokenizer_config.json
└── README.md
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Step2:修改运行环境配置
[1] 使用MPS进行加速推理
PDF-Extract-Kit/configs/model_configs.yaml:2
device: mps
PDF-Extract-Kit/modules/layoutlmv3/layoutlmv3_base_inference.yaml:72
DEVICE: mps
[2] 使用CPU进行推理
PDF-Extract-Kit/configs/model_configs.yaml:2
device: cpu
PDF-Extract-Kit/modules/layoutlmv3/layoutlmv3_base_inference.yaml:72
DEVICE: cpu
# 2.2.3 运行程序提取文档内容
$ python3 pdf_extract.py --vis --pdf ./assets/examples/example.pdf
参数含义:
- --pdf:需要处理的PDF文件;如果传入的是文件夹,则会处理该文件夹中的所有PDF文件。
- --output:结果保存路径,默认为“output”。
- --vis:是否可视化结果;如果是,包括边界框和类别的检测结果将被可视化。
- --render:是否渲染识别结果,包括公式的LaTeX代码和纯文本,这些将被渲染并放置在检测框中。注意:这个过程非常耗时,并且还需要先安装xelatex和imagemagic。
官方说在一些较新的 M 芯片设备上,MPS 加速无法激活,实测我这个 M1 Pro 芯片也无法使用 MPS 加速推理。

因为我最终是使用CPU去运行的,所以推理速度很慢,使用官方测试文件耗时786s才处理完。

输出会给出一个json和一个pdf,实测的提取效果如下:

局限性:布局识别后的文本提取效果不好。
# 2.3 MinerU简介及使用实例
# 2.3.1 MinerU简介
MinerU 不仅能将混合了图片、公式、表格、脚注等在内的复杂多模态 PDF 文档精准转化为清晰、易于分析的 Markdown 格式;同时支持从包含广告等各种干扰信息或者复杂格式的网页、电子书中快速解析、抽取正式内容。有效提高AI语料准备效率,助力各行业利用大模型、RAG等技术,结合学术文献、财务报告、法律文件、电子书籍等专业文档,打造垂直领域的新知识引擎。

# 2.3.2 MinerU使用实例
实验环境:实体GPU服务器,NVIDIA RTX 4090 / 24GB,CentOS 7.9,Anaconda3-2019.03,CUDA 12.4
原先实验PDF-Extract-Kit时已经将模型文件下载过了,这里就不必重复下载了,复用即可。
Step1:安装MinerU依赖环境
$ conda create -n MinerU python=3.10
$ conda activate MinerU
$ pip3 install magic-pdf[full]==0.7.0b1 --extra-index-url https://wheels.myhloli.com
2
3
Step2:创建配置文件
在用户目录(Linux可使用echo $HOME命令查看)创建配置文件magic-pdf.json,配置模板可从 magic-pdf.template.json (opens new window) 来获取。
{
"models-dir":"/your_model_path/models",
"device-mode":"cuda",
"table-config": {
"is_table_recog_enable": false,
"max_time": 400
}
}
2
3
4
5
6
7
8
Step3:使用MinerU解析文档
magic-pdf --help
Usage: magic-pdf [OPTIONS]
Options:
-v, --version display the version and exit
-p, --path PATH local pdf filepath or directory [required]
-o, --output-dir TEXT output local directory
-m, --method [ocr|txt|auto] the method for parsing pdf.
ocr: using ocr technique to extract information from pdf,
txt: suitable for the text-based pdf only and outperform ocr,
auto: automatically choose the best method for parsing pdf
from ocr and txt.
without method specified, auto will be used by default.
--help Show this message and exit.
## show version
magic-pdf -v
## command line example
magic-pdf -p {some_pdf} -o {some_output_dir} -m auto
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
以yolov9论文为例,输出结果包含以下内容:
.
├── images
├── layout.pdf
├── middle.json
├── model.json
├── origin.pdf
├── spans.pdf
└── yolov9.md
2
3
4
5
6
7
8
布局划分的效果如下,可以看到将需要提取的模块已经准确识别了。

公式提取效果如下,可以看到已经将公式解析成LaTeX了。

局限性:1)提取的md文件中标题没有层级。2)对于双栏中文文本提取效果较差,布局能够正确识别,但是输出为文本后混乱。3)对于图注在图片上方的图片提取效果较差。
# 2.3.3 MinerU踩坑记录
[1] 最初我是在 M1 的 macOS 上运行时,报错“illegal hardware instruction”,不知道是不是有兼容问题,又将其挪到了Linux上去运行。
[2] 在Linux上运行时又出现 /lib64/libstdc++.so.6: version `GLIBCXX_3.4.20' not found 报错。
Step1:首先使用如下命令进行查询,发现我的确没有3.4.20版本。
$ strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
Step2:然后我使用find命令进行查询,发现服务器上有满足要求的库
$ find / -name "libstdc++.so*"
Step3:备份原来的库文件,再设置软链接(根据上一步的查询结果来设置),这时进行查询就有3.4.20版本了。
$ sudo mv /usr/lib64/libstdc++.so.6 /usr/lib64/libstdc++.so.6.bak
$ sudo ln -s /root/anaconda3/lib/libstdc++.so.6.0.25 /usr/lib64/libstdc++.so.6
$ strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
注:如果实验完了需要还原,可以执行如下命令:
$ sudo mv /usr/lib64/libstdc++.so.6.bak /usr/lib64/libstdc++.so.6
2
3
4
5
6
7
8
9
10
11
12
# 2.4 MinerU的容器化API服务
实验环境:Debian12,512GB内存,256TB存储,Docker version 20.10.24、NVIDIA RTX 4090 / 24GB、CUDA 12.6
# 2.4.1 搭建MinerU的API服务
使用 nvidia-smi 命令查一下显卡的占用情况,找一个显存充足的显卡用于部署(我在实际部署时占用了6200MB的显存),换掉 --gpus device=2 参数即可。
$ docker pull registry.cn-beijing.aliyuncs.com/quincyqiang/mineru:0.2-models
$ docker run -itd --name=mineru_server --gpus device=2 -p 8000:8000 registry.cn-beijing.aliyuncs.com/quincyqiang/mineru:0.2-models
2
注:作者的这个镜像里使用的依赖环境是GPU版的,CPU下无法直接运行,如果要用的话要自己去换依赖,使用CPU的推理速度很慢,没啥实际使用的价值,没GPU建议不要用了。
# 2.4.2 使用MinerU的API服务
使用 Chrome 访问 http://ip:8000/docs 地址即可查看接口文档,支持的参数如下:
- pdf_file: 需要解析的PDF文件。
- parse_method: 解析方法,支持 "auto"、"ocr" 或 "txt" 三种方式。默认是 "auto"。如果解析结果不满意,可以尝试使用 "ocr" 方法。
- model_json_path: 已有模型数据文件的路径。如果为空,将使用内置模型。PDF文件和模型文件必须对应。
- is_json_md_dump: 是否将解析的数据写入 .json 和 .md 文件。默认为True。数据的不同阶段将分别保存到3个不同的 .json 文件中,md内容将保存到 .md 文件中。
- output_dir: 结果输出目录。将在该目录下创建一个以PDF文件命名的文件夹,用于存储所有结果。
这里我将 is_json_md_dump 参数设置成 false,然后上传了一篇 yolov9的论文进行测试。

这篇论文有18页,在该GPU环境下耗时28s获取到了结果,提取的速度和效果看起来还行。

注:涉及图片的部分,返回值里是相对引用,存放在容器内 /tmp/文件名/images 目录下。
# 2.5 MinerU解析流程拆解
# 2.5.1 解析流程拆解
这里以 v1.3.10 版本为例,深入拆解下它进行文档解析时的内部操作细节。

下面根据官方提供的运行示例,一步步拆解具体的流程。
import os
# 导入必要的模块和类
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod
# 参数设置
pdf_file_name = "file.pdf" # 要处理的PDF文件路径,使用时替换为实际路径
name_without_suff = pdf_file_name.split(".")[0] # 去除文件扩展名
# 准备环境
local_image_dir, local_md_dir = "output/images", "output" # 图片和输出目录
image_dir = str(os.path.basename(local_image_dir)) # 获取图片目录名
# 创建输出目录(如果不存在)
os.makedirs(local_image_dir, exist_ok=True)
# 初始化数据写入器
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# 读取PDF文件内容
reader1 = FileBasedDataReader("") # 初始化数据读取器
pdf_bytes = reader1.read(pdf_file_name) # 读取PDF文件内容为字节流
# 处理流程
## 创建PDF数据集实例
ds = PymuDocDataset(pdf_bytes) # 使用PDF字节流初始化数据集
## 推理阶段
if ds.classify() == SupportedPdfParseMethod.OCR:
# 如果是OCR类型的PDF(扫描件/图片型PDF)
infer_result = ds.apply(doc_analyze, ocr=True) # 应用OCR模式的分析
## 处理管道
pipe_result = infer_result.pipe_ocr_mode(image_writer) # OCR模式的处理管道
else:
# 如果是文本型PDF
infer_result = ds.apply(doc_analyze, ocr=False) # 应用普通文本模式的分析
## 处理管道
pipe_result = infer_result.pipe_txt_mode(image_writer) # 文本模式的处理管道
### 绘制模型分析结果到每页PDF
infer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))
### 获取模型推理结果
model_inference_result = infer_result.get_infer_res()
### 绘制布局分析结果到每页PDF
pipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))
### 绘制文本块(span)分析结果到每页PDF
pipe_result.draw_span(os.path.join(local_md_dir, f"{name_without_suff}_spans.pdf"))
### 获取Markdown格式的内容
md_content = pipe_result.get_markdown(image_dir) # 包含图片相对路径
### 保存Markdown文件
pipe_result.dump_md(md_writer, f"{name_without_suff}.md", image_dir)
### 获取内容列表(JSON格式)
content_list_content = pipe_result.get_content_list(image_dir)
### 保存内容列表到JSON文件
pipe_result.dump_content_list(md_writer, f"{name_without_suff}_content_list.json", image_dir)
### 获取中间JSON格式数据
middle_json_content = pipe_result.get_middle_json()
### 保存中间JSON数据
pipe_result.dump_middle_json(md_writer, f'{name_without_suff}_middle.json')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
[1] 数据读取
调用:magic_pdf\data\data_reader_writer\filebase.py中FileBasedDataReader的read_at方法
def read_at(self, path: str, offset: int = 0, limit: int = -1) -> bytes:
"""Read at offset and limit.
Args:
path (str): the path of file, if the path is relative path, it will be joined with parent_dir.
offset (int, optional): the number of bytes skipped. Defaults to 0.
limit (int, optional): the length of bytes want to read. Defaults to -1.
Returns:
bytes: the content of file
"""
fn_path = path
if not os.path.isabs(fn_path) and len(self._parent_dir) > 0:
fn_path = os.path.join(self._parent_dir, path)
with open(fn_path, 'rb') as f:
f.seek(offset)
if limit == -1:
return f.read()
else:
return f.read(limit)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
可设定offset和limit两个参数:
- offset:控制读取时的偏移量,比如从第n个字符后开始读取
- limit:控制读取的长度,比如读取n个字符
默认读取文件所有内容,以二进制形式读取,直接加载进内存。如果文件特别大,可以考虑用这两个参数做分批读取。
[2] 文件类型分类
对于PDF文件,进一步判断是图片型PDF(扫描件)还是文本型PDF。具体判断逻辑在magic_pdf\filter\pdf_classify_by_type.py的classify函数:
def classify(total_page: int, page_width, page_height, img_sz_list: list, text_len_list: list, img_num_list: list,invalid_chars: bool):
results = {
'by_image_area': classify_by_area(total_page, page_width, page_height, img_sz_list, text_len_list),
'by_text_len': classify_by_text_len(text_len_list, total_page),
'by_avg_words': classify_by_avg_words(text_len_list),
'by_img_num': classify_by_img_num(img_sz_list, img_num_list),
# 'by_text_layout': classify_by_text_layout(text_layout_list),
'by_img_narrow_strips': classify_by_img_narrow_strips(page_width, page_height, img_sz_list),
'by_invalid_chars': invalid_chars,
}
2
3
4
5
6
7
8
9
10
这里进行了多方面的判断,具体方式如下:
- classify_by_area 如果 PDF 里大部分页面(超过一半)的主要内容都是一张大图片(图片面积占了页面面积的一半以上),那就认为这个 PDF 是扫描件,需要 OCR 处理,否则认为这个 PDF 是文本型的(返回 True)。在判断前,它会先尝试去掉水印图片,并把可能被切成小块的图片拼起来。
- classify_by_text_len 随机抽取一部分页面,只要其中任何一页的文字数量超过 100 个字符,就认为这个 PDF 是文本型的(返回 True)。
- classify_by_avg_words 计算 PDF 所有页面的平均字符数,如果平均每页字符数超过 100,就认为这个 PDF 是文本型的(返回 True)。
- classify_by_img_num 检查 PDF 是否属于一种特殊扫描件,其特点是:去除重复图片后,几乎每页都没有有效图片了,但原始图片数量在大部分页面上都非常多且数量一致。如果不是这种情况,就认为它是文本型 PDF(返回 True)。
- classify_by_img_narrow_strips 检查 PDF 是否有一半以上的页面,其绝大部分图片(至少 5 张且占该页图片总数的 80% 以上)都是非常细长的(即宽度占页面宽度的 90% 以上且至少是高度的 4 倍,或者高度占页面高度的 90% 以上且至少是宽度的 4 倍)。如果这种情况的页面比例低于 50%,则认为 PDF 在这个维度上倾向于是文本型的(返回 True)。
- invalid_chars 在扫描 PDF 文件内容时,是否检测到了无效或无法正常显示的字符,如果没有,判定为文本型(返回 True)。
最后,综合这6个条件,如果这6个条件都为True,即判定文件是文本型的PDF,有任意条件不通过,则判定文件为图片型PDF。
[3] 设备选择
在正式处理前,需要先指定运行设备。首先需要读取配置文件,相关代码在MinerU\magic_pdf\libs\config_reader.py
# 定义配置文件名常量
CONFIG_FILE_NAME = os.getenv('MINERU_TOOLS_CONFIG_JSON', 'magic-pdf.json')
def read_config():
if os.path.isabs(CONFIG_FILE_NAME):
config_file = CONFIG_FILE_NAME
else:
home_dir = os.path.expanduser('~')
config_file = os.path.join(home_dir, CONFIG_FILE_NAME)
ifnot os.path.exists(config_file):
raise FileNotFoundError(f'{config_file} not found')
with open(config_file, 'r', encoding='utf-8') as f:
config = json.load(f)
return config
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
代码表明,它会根据系统环境变量MINERU_TOOLS_CONFIG_JSON去查找json的配置文件。如果未设置此环境变量,默认会到用户home目录下,寻找magic-pdf.json这个文件。
该文件中,device-mode设定了模型运行的设备,有cpu、cuda、npu三种模式进行选择(如果填入值非这三类,视作cpu)。如果选择了cuda或npu,会自动计算显存容量,并自适应调节batch_ratio,具体调节规则如下:
if gpu_memory >= 16:
batch_ratio = 16
elif gpu_memory >= 12:
batch_ratio = 8
elif gpu_memory >= 8:
batch_ratio = 4
elif gpu_memory >= 6:
batch_ratio = 2
else:
batch_ratio = 1
2
3
4
5
6
7
8
9
10
对于CPU设备,batch_ratio默认设为1。除此之外,在配置文件中,无法显性指定多卡同时解析,如有多卡解析的需求,可参考基于 LitServe 的多 GPU 并行处理方案,详见:https://github.com/opendatalab/MinerU/tree/master/projects/multi_gpu (opens new window)
[4] 解析处理
具体的处理流程在magic_pdf\model\batch_analyze.py。图片型PDF会比文本型PDF多一个OCR处理的步骤,其它步骤一致。
1)布局分析
布局分析提供了两套模型可供选择:layoutlmv3和doclayout_yolo,默认用后者,DocLayout-YOLO (opens new window) 也是OpenDataLab的。该算法是基于YOLO-v10对文件布局标记的数据集D4LA和DocSynth300K进行训练,从而检测出不同的布局信息。

2)公式处理
公式处理包含两个阶段:公式检测(MFD)和 公式识别(MFR)。
- 公式检测是指检测出公式所在位置,采用
yolo_v8_mfd算法,未找到该算法的详细介绍,根据揣测是采用yolov8算法,在公式块标记的相关数据集上进行训练得到。 - 公式识别是指在得到公式区域的基础上,识别其中的具体内容,将其中的数学表达式图像转换为 LaTeX ,具体算法采用 UniMERNet (opens new window)算法,该算法也是OpenDataLab的自研算法。
考虑到并不是所有的PDF文件中都有公式,因此,可以在配置文件中,将其关闭。默认的"enable"设置为开启状态,如需关闭公式处理,设为false。
"formula-config": {
"mfd_model": "yolo_v8_mfd",
"mfr_model": "unimernet_small",
"enable": true
},
2
3
4
5
3)OCR处理
OCR是指将图像区域内容识别成文本,和公式处理类似,同样包含区域检测和区域识别两个阶段。这两个阶段均是使用PaddleOCR,该算法原生使用的PaddlePaddle框架,这里使用了Pytorch的实现版本。
在magic_pdf\model\sub_modules\ocr\paddleocr2pytorch\pytorch_paddle.py中,有一个测试样例。对于不同的语言进行OCR,使用不同的模型,在magic_pdf\model\sub_modules\ocr\paddleocr2pytorch\pytorchocr\utils\resources\models_config.yml这个配置文件,规定了不同语言所对应的采取的不同模型。
对于中文,检测模型使用ch_PP-OCRv3_det_infer,识别模型采用ch_PP-OCRv4_rec_infer。在下载模型时,会将所有常见语言(中文、英文、日文、拉丁文等语言)的模型一次性下载下来,每个模型体积不大,基本在10-20MB左右。
4)表格识别
表格识别包含两个部分:表格文本识别和表格结构识别,该部分代码来自 RapidTable (opens new window) 仓库。
- 表格文本识别默认采用
rapid_table这个依赖库,底层同样使用的是PaddleOCR,用来识别表格中的文本内容。 - 表格结构识别默认采用
slanet_plus算法,用来识别表格结构。
表格识别同样可以在配置文件中自由选择关闭,和公式处理一样,通过enable参数来控制开启和关闭。
"table-config": {
"model": "rapid_table",
"sub_model": "slanet_plus",
"enable": true,
"max_time": 400
},
2
3
4
5
6
5)结果输出
最后可输出结果包括:
- model.pdf:布局分析的可视化结果
- file_layout.pdf:布局分析后,去除页眉页脚,标记真正内容的可视化结果
- spans.pdf:文本/图像/公式/表格区域检测的可视化结果
- middle.json:每一区域识别的中间结果
- content_list.json:分块内容识别结果,对每段落的小块区域进行合并
具体的相关接口参见magic_pdf\operators\pipes.py
# 2.5.2 其它文件处理
由于MinerU是针对PDF进行解析,因此本身的处理管道并不能处理其它格式的文件。
在v1.0.1版本后,进一步支持图像(.jpg及.png)、Word(.doc及.docx)、以及PPT(.ppt及.pptx)三类文件的解析。
[1] MS-Office文件解析
对于 MS-Office 文件,需要通过 LibreOffice 将其转换成 PDF文件,再复用PDF的解析管道。(本地使用时,需要提前安装LibreOffice,并设置相应环境变量)
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.data.read_api import read_local_office
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# proc
## Create Dataset Instance
input_file = "demo.pptx" # replace with real ms-office file
input_file_name = input_file.split(".")[0]
ds = read_local_office(input_file)[0]
infer_result = ds.apply(doc_analyze, ocr=True)
## 处理管道
pipe_result = infer_result.pipe_ocr_mode(image_writer)
pipe_result.dump_md(md_writer, f"{input_file_name}.md", image_dir)
### 获取内容列表(JSON格式)
content_list_content = pipe_result.get_content_list(image_dir)
### 保存内容列表到JSON文件
pipe_result.dump_content_list(md_writer, f"{input_file_name}_content_list.json", image_dir)
### 获取中间JSON格式数据
middle_json_content = pipe_result.get_middle_json()
### 保存中间JSON数据
pipe_result.dump_middle_json(md_writer, f'{input_file_name}_middle.json')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
具体转换过程在magic_pdf\data\read_api.py文件的read_local_office方法。
[2] 图片文件解析示例
对于图片文件,无需转换成pdf,原本的管道可兼容,示例python脚本如下:
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.data.read_api import read_local_images
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# proc
## Create Dataset Instance
input_file = "demo.jpg" # replace with real image file
input_file_name = input_file.split(".")[0]
ds = read_local_images(input_file)[0]
infer_result = ds.apply(doc_analyze, ocr=True)
## 处理管道
pipe_result = infer_result.pipe_ocr_mode(image_writer)
pipe_result.dump_md(md_writer, f"{input_file_name}.md", image_dir)
### 获取内容列表(JSON格式)
content_list_content = pipe_result.get_content_list(image_dir)
### 保存内容列表到JSON文件
pipe_result.dump_content_list(md_writer, f"{input_file_name}_content_list.json", image_dir)
### 获取中间JSON格式数据
middle_json_content = pipe_result.get_middle_json()
### 保存中间JSON数据
pipe_result.dump_middle_json(md_writer, f'{input_file_name}_middle.json')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 3. Marker文档解析
Marker是一个将PDF文档转换Markdown的库,OmniParse文档解析平台是基于Marker来实现的。
# 3.1 Marker将文档转换Markdown
# 3.1.1 Marker简介
Marker能将PDF、EPUB和MOBI转换为Markdown。它比nougat快10倍,对大多数文档的准确度更高,并且幻觉风险低。
- 支持各种PDF文档(针对书籍和科学论文进行优化)
- 移除页眉/页脚/其他杂项
- 将大部分方程式转换为LaTeX
- 格式化代码块和表格
- 支持多种语言(尽管大部分测试都是用英语完成),查看settings.py以获取语言列表
- 可在GPU、CPU或MPS上运行
项目地址:https://github.com/VikParuchuri/marker (opens new window)

# 3.1.2 Marker使用实例
[1] 准备运行环境
实验环境:Macbook Pro 2021,M1 Pro芯片,16G内存,macOS Ventura13.2.1系统,Python3.9环境
$ git clone https://github.com/VikParuchuri/marker.git
$ pip3 install -r requirements.txt
$ pip3 install -r scripts/install/brew-requirements.txt
2
3
使用官方requirements安装完依赖后,我这里有各种报错,又安装了如下依赖才成功跑起来。
$ brew install tesseract-lang
$ brew install ghostscript
$ brew install libmagic
$ pip3 install ftfy
$ pip3 install pyspellchecker
$ pip3 install ocrmypdf
$ pip3 install thefuzz
$ pip3 uninstall nougat
$ pip3 install nougat-ocr
$ pip3 install --upgrade transformers
$ pip3 install python-magic
$ pip3 install ray
报错信息:ImportError: cannot import name 'NougatModel' from 'nougat'
解决方案:不要安装 Nougat,只需安装 Nougat-OCR。pip3 uninstall nougat 及 pip3 install nougat-ocr
报错信息:ValueError: Non-consecutive added token '<pad>' found. Should have index 259 but has index 0 in saved vocabulary.
解决方案:更新transformers即可。pip3 install --upgrade transformers
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
[2] 解析PDF文档
这里以转换单个文件为例,首次执行时,会自动下载模型。官方支持对文档进行批处理,也有很多超参可以控制转换配置,详见官方README,这里就不赘述了。
$ python3 convert_single.py input/input.pdf output/output.md --parallel_factor 20
--parallel_factor 是批量大小和并行 OCR 工作人员增加多少。数字越大,需要的 VRAM 和 CPU 越多,但处理速度越快,默认设置为 1。

注:这个工具只提取PDF文档里的文本,表格什么的也能解析,但对于图表,解析时会将其丢弃。
# 3.1.3 将Marker封装成Docker
实验环境:Debian 11 x86_64、Docker version 20.10.17、无GPU。
- 将Marker封装成Docker,方便在其他服务器环境上迁移部署。
- 实测安装依赖及模型需要占用大约12GB存储,运行时至少需要4GB内存,对资源的占用要求还是不小的。
requirements.txt
scikit-learn == 1.3.2
Pillow == 10.1.0
pytesseract == 0.3.10
PyMuPDF == 1.23.5
pymupdf-fonts == 1.0.5
pydantic == 2.4.2
pydantic-settings == 2.0.3
nougat-ocr == 0.1.17
transformers == 4.34.1
numpy == 1.26.1
python-dotenv == 1.0.0
torch == 2.1.1
ray == 2.7.1
tqdm == 4.66.1
tabulate == 0.9.0
thefuzz == 0.20.0
python-magic == 0.4.27
pyspellchecker == 0.7.2
ftfy == 6.1.1
nltk == 3.8.1
ocrmypdf == 15.4.0
bitsandbytes == 0.41.2.post2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Dockerfile
# 基于python3.9镜像创建新镜像
FROM python:3.9
# 创建容器内部目录
RUN mkdir /code
# 将项目复制到内部目录
ADD . /code/
# 切换到工作目录
WORKDIR /code
# 安装项目依赖
RUN pip install -r requirements.txt
# 安装vim命令
RUN apt-get update && apt-get install vim -y
2
3
4
5
6
7
8
9
10
11
12
build.sh
#!/bin/bash
base_path=$(cd `dirname $0`; pwd)
input_path="${base_path}/input"
output_path="${base_path}/output"
docker build -t marker-image .
docker run -itd --name marker -v ${input_path}:/code/input -v ${output_path}:/code/output marker-image:latest
docker update marker --restart=always
2
3
4
5
6
7
8
9
新建 input 和 output 目录,执行 build.sh 脚本构建镜像与容器,之后在 input 目录上传用于测试的 PDF 文件,进入容器执行。
$ docker exec -it marker /bin/bash
$ python3 convert_single.py input/input.pdf output/output.md --parallel_factor 1
2
# 3.2 OmniParse文档解析平台
# 3.2.1 OmniParse简介
OmniParse 是一个能够将各种非结构化数据(如文档、图片、视频等)转换为结构化数据的开源平台。它支持20多种文件类型,所有的数据处理都在本地完成,不需要通过外部API,从而确保用户的数据隐私和安全。

# 3.2.2 OmniParse搭建
实验环境:实体GPU服务器,NVIDIA RTX 4090 / 24GB,CentOS 7.9,Anaconda3-2019.03,CUDA 12.4
$ docker pull savatar101/omniparse:0.1
$ docker run -itd --name omniparse --gpus all -p 8000:8000 -e HF_ENDPOINT=https://hf-mirror.com savatar101/omniparse:0.1 python server.py --host 0.0.0.0 --port 8000 --documents --media
$ docker logs -f omniparse
2
3
注意事项:因为国内网络环境的缘故,遇到了一些坑。
- 因为要从Huggingface下载模型,而国内网络不能直连,因此设置了
-e HF_ENDPOINT=https://hf-mirror.com镜像源,若是境外网络则不需要此配置。 - 也有可能是国内网络的原因,我运行到 Loading Web Crawler 阶段就会报错,而 Web Crawler 我并不需要,因此在 docker run 时重写覆盖了Dockerfile里的CMD命令,将 --web 去掉了。
# 3.2.3 OmniParse使用
使用 Chrome 浏览器打开 http://ip:8000 地址,即可通过Web的方式使用 OmniParse 工具。

OmniParse的提取效果如下:

其中提取出的图片是单独列出的:

除此之外,OmniParse还支持输出JSON格式的提取结果,并支持API调用。

# 4. DeepDoc文档解析
# 4.1 DeepDoc简介
DeepDoc是RAGFlow开源项目中提出的一个支持多种文本切片的解析模版,它利用视觉信息和解析技术,对文档进行深度理解,提取文本、表格和图像等信息。它的功能模块包括:
- 布局识别:使用 Yolov8 进行布局识别/OCR/TSR,识别文档的布局结构,例如标题、段落、表格、图像等。
- OCR识别:支持多种语言和字体,并能够处理复杂的文档布局和图像质量。
- TSR识别:识别表格的结构,例如行列、表头、单元格合并等,并将其转换为自然语言句子。
- 文档解析:支持解析 PDF、DOCX、EXCEL 和 PPT 等多种文档格式,并提取文本块、表格和图像等信息。
- 简历解析:将简历中的非结构化文本解析为结构化数据,例如姓名、联系方式、工作经历、教育背景等。
官方详细介绍:https://github.com/infiniflow/ragflow/blob/main/deepdoc/README.md (opens new window)
# 4.2 DeepDoc使用实例
实验环境:Macbook Pro 2021,M1 pro芯片,16G内存,macOS Ventura13.2.1系统,Python3.9环境
# 4.2.1 OCR光学字符识别
OCR(Optical Character Recognition,光学字符识别)
由于许多文档都是以图像形式呈现的,或者至少能够转换为图像,因此OCR是文本提取的一个非常重要、基本,甚至通用的解决方案。
$ python3 deepdoc/vision/t_ocr.py -h
usage: t_ocr.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR]
options:
-h, --help show this help message and exit
--inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
--output_dir OUTPUT_DIR
Directory where to store the output images. Default: './ocr_outputs'
2
3
4
5
6
7
8
使用实例:输入可以是图像或PDF的目录,也可以是图像或PDF,输出是每一页的TXT与JPG。
$ python3 deepdoc/vision/t_ocr.py --inputs=./data/yolov9论文.pdf --output_dir=./output

# 4.2.2 TSR表结构识别
TSR(Table Structure Recognition,表结构识别)
数据表是一种常用的结构,用于表示包括数字或文本在内的数据。表的结构可能非常复杂,比如层次结构标题、跨单元格和投影行标题。除了TSR,我们还将内容重新组合成LLM可以很好理解的句子。TSR任务有五个标签:列、行、列标题、行标题、合并单元格。
$ python3 deepdoc/vision/t_recognizer.py -h
usage: t_recognizer.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR] [--threshold THRESHOLD] [--mode {layout,tsr}]
options:
-h, --help show this help message and exit
--inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
--output_dir OUTPUT_DIR
Directory where to store the output images. Default: './layouts_outputs'
--threshold THRESHOLD
A threshold to filter out detections. Default: 0.5
--mode {layout,tsr} Task mode: layout recognition or table structure recognition
2
3
4
5
6
7
8
9
10
11
使用实例:输入可以是图像或PDF的目录,也可以是图像或PDF,输出是每一页的HTML与JPG。
$ python3 deepdoc/vision/t_recognizer.py --inputs=./data/住宿标准.pdf --output_dir=./output --threshold=0.2 --mode=tsr

# 5. Docling文档解析
# 5.1 Docling简介
Docling是一个开源文档解析和转换工具,能高效地将多种格式的文档(PDF、DOCX、PPTX、图片和HTML)解析导出为Markdown或JSON格式。Docling支持高级PDF理解、OCR功能,能与LlamaIndex和LangChain等工具集成,增强文档的检索和问答能力。
- 项目地址:https://github.com/DS4SD/docling (opens new window)
- 技术报告:https://arxiv.org/abs/2408.09869 (opens new window)

# 5.2 Docling使用
# 5.2.1 依赖环境
实验环境:Macbook Pro 2021,M1 pro芯片,16G内存,macOS Sonoma 14.5系统,Python3.10环境
依赖安装:需要在Python3.10环境下进行安装,我试过Python3.9和Python3.11,都安装失败了。
$ pip3 install docling --index-url https://pypi.org/simple/
# 5.2.2 调用代码
Docling的使用非常简单,支持命令行Cli和代码调用,我这里使用后者作为示例:
# -*- coding: utf-8 -*-
from docling.document_converter import DocumentConverter
# source = "https://arxiv.org/pdf/2408.09869" # document per local path or URL
source = "./test.docx"
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown())
2
3
4
5
6
7
8
9
注:支持很多种方式的提取和转换,这里只是最简单的示例,详见官方文档:https://ds4sd.github.io/docling/examples/minimal (opens new window)
# 5.2.3 解析效果
首次执行脚本会自动下载模型,它的提取速度和转换效果是很不错的,对于表格处理的也比较精确。

局限性:1)对于没有明显层级的pdf文件,提取的md标题层级不明显。2)不支持提取图片,只能提取到图注。
# 6. MarkitDown文档解析
# 6.1 MarkitDown简介
MarkItDown是微软开源的文档处理工具,它能将PDF、PPT、Word、Excel、图像、音频、HTML等多种格式的文件转换成Markdown格式。支持OCR文字识别、语音转文字和元数据提取,适用于内容索引、数据挖掘、文档处理等场景。
MarkItDown技术原理:
- 文件解析:用不同的解析器读取和解析各种文件格式的内容。
- 文本提取与转换
- 对于文档类文件(如Word、Excel、PowerPoint),将文档内容转换为纯文本,并保留结构化信息(如标题、列表等)适应Markdown格式。
- 对于图像文件,用OCR技术(光学字符识别)识别图像中的文本,转换为文本格式。
- 元数据处理:对于图像和音频文件,提取EXIF元数据,一种存储在文件中的标准化信息,包括文件的创建时间、作者、设备信息等。
- 语音转录:对于音频文件,用语音识别技术将语音内容转录成文本。
# 6.2 MarkitDown使用
# 6.2.1 依赖环境
实验环境:Macbook Pro 2021,M1 pro芯片,16G内存,macOS Sonoma 14.5系统,Python3.10环境
$ pip3 install markitdown
# 6.2.2 调用方式
官方支持Python代码调用、命令行调用、Docker容器调用等方式。
对于文档:
# -*- coding: utf-8 -*-
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("test.xlsx")
print(result.text_content)
2
3
4
5
6
7
对于图片:
# -*- coding: utf-8 -*-
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
result = md.convert("test.png")
print(result.text_content)
2
3
4
5
6
7
8
9
10
注:MarkItDown 依赖 LLM 来生成图像描述,如果没有没有提供有效的 LLM,将不会提取到任何内容。
# 6.2.3 解析效果
MarkitDown是微软开源的,它对于Office系列文档的解析效果是很不错的,而且速度很快。但对于图像、PDF等格式就没有什么优势了。

# 7. ZeroX-OCR文档解析
# 7.1 ZeroX-OCR简介
# 7.1.1 基本介绍
ZeroX-OCR是一个简单易用的OCR工具,可将PDF、DOCX等文件转换为Markdown格式。它使用视觉大模型模型对每个页面进行OCR处理,并将结果聚合为最终的Markdown输出。该工具支持Node.js和Python两种语言,并提供了丰富的配置选项。
- 项目地址:https://github.com/getomni-ai/zerox (opens new window)
- 官方网址:https://getomni.ai/ocr-demo (opens new window)

# 7.1.2 核心逻辑
Zerox的核心逻辑是:将输入文件(PDF、DOCX等)转换为一系列图像,然后将每个图像传递给视觉模型,请求生成Markdown,最后将所有Markdown片段聚合起来返回最终结果。
# 7.1.3 格式支持
Zerox 使用 libreoffice 和 graphicsmagick 进行文档到图像的转换,支持以下文件类型:
[
"pdf", // Portable Document Format
"doc", // Microsoft Word 97-2003
"docx", // Microsoft Word 2007-2019
"odt", // OpenDocument Text
"ott", // OpenDocument Text Template
"rtf", // Rich Text Format
"txt", // Plain Text
"html", // HTML Document
"htm", // HTML Document (alternative extension)
"xml", // XML Document
"wps", // Microsoft Works Word Processor
"wpd", // WordPerfect Document
"xls", // Microsoft Excel 97-2003
"xlsx", // Microsoft Excel 2007-2019
"ods", // OpenDocument Spreadsheet
"ots", // OpenDocument Spreadsheet Template
"csv", // Comma-Separated Values
"tsv", // Tab-Separated Values
"ppt", // Microsoft PowerPoint 97-2003
"pptx", // Microsoft PowerPoint 2007-2019
"odp", // OpenDocument Presentation
"otp", // OpenDocument Presentation Template
];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 7.2 ZeroX-OCR使用
# 7.2.1 依赖环境
实验环境:Debian 11 x86_64 系统,8GB内存,160GB存储,Python 3.11
$ sudo apt install poppler-utils
$ conda create -n zerox python=3.11 -c conda-forge
$ conda activate zerox
$ pip3 install py-zerox
2
3
4
# 7.2.2 调用代码
将如下代码中的 OPENAI_API_KEY 和 OPENAI_API_BASE 换成自己的,模型选择具备视觉模态能力的即可。
from pyzerox import zerox
import os
import asyncio
model = "gpt-4o"
os.environ["OPENAI_API_KEY"] = "sk-xxx"
os.environ["OPENAI_API_BASE"] = "https://xxx.xxx.xxx/v1"
async def main():
file_path = "./test.pdf"
output_dir = "./output_test"
result = await zerox(file_path=file_path, model=model, output_dir=output_dir)
return result
result = asyncio.run(main())
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 7.2.3 解析效果
对于文本、表格类的内容处理还凑合,但论文内容顺序都乱了,而且图片也全弄没了,公式也渲染不出来了,整体感觉解析效果不咋地。
而且由于需要视觉大模型API,推理成本较高,测试的这篇论文18页,消耗了483.1k的Token,大批量处理的话,不得不考虑成本问题。

# 8. Agentic Doc文档解析
# 8.1 Agentic Doc简介
Agentic Doc 是一个由 LandingAI 提供的 Python 库,用于从视觉复杂的文档(如包含表格、图片和图表的文件)中提取结构化数据,并以层级 JSON 格式返回元素精确位置。
- 支持长文档处理,可一次性解析超过 100 页甚至上千页的 PDF 文件
- 自动重试与分页机制,能应对并发、超时及速率限制问题
- 提供辅助工具,如边界框截图和可视化调试功能,方便结果验证
- 安装简便,仅需通过 pip 即可使用,无额外依赖
- 支持多种文件类型,包括任意长度 PDF、本地图片及网络 URL 指向的文件
- 输出格式丰富,既有层级结构化 JSON,也支持直接渲染 Markdown 文本
- 批量与并行处理能力强,可自动管理线程数和请求速率限制
- 配置灵活,通过环境变量或 .env 文件调整参数,无需修改代码
- 同时提供底层 REST API 访问接口,满足高级用户需求
支持的文件格式:PDF、图片(OpenCV-Python支持的格式)及对应的URL
项目地址:https://github.com/landing-ai/agentic-doc (opens new window)(该库并未开源,本仓库只是放了些调用代码,需要申请API-KEY才能用)。
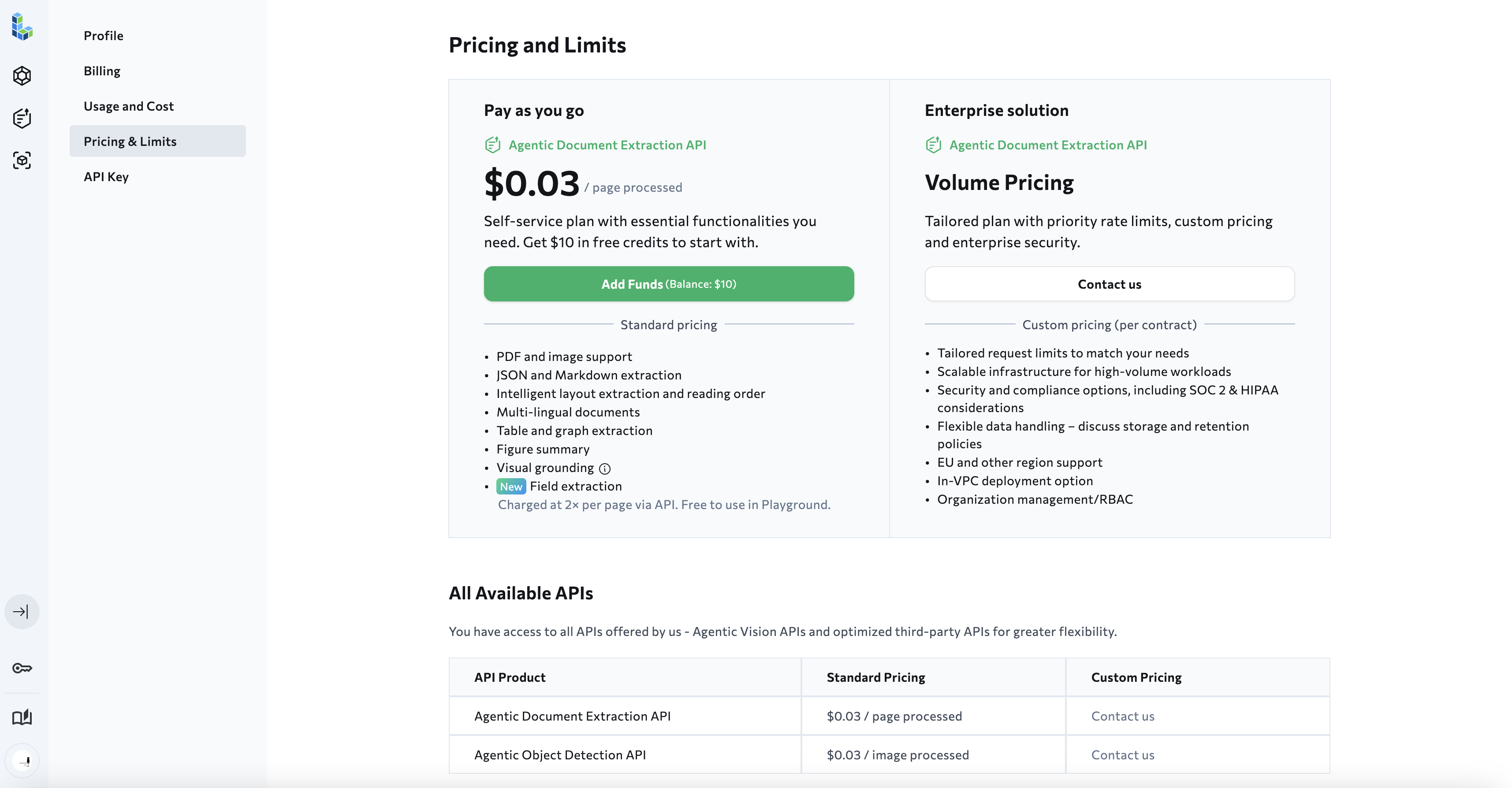
# 8.2 Agentic Doc使用
# 8.2.1 安装并申请密钥
官方要求 Python 版本为 3.9、3.10、3.11 或 3.12,安装依赖库:
$ pip3 install agentic-doc
获取 LandingAI Agentic Doc 的 API-KEY:https://va.landing.ai/settings/api-key (opens new window)(注册后会赠送$10的试用体验额度)
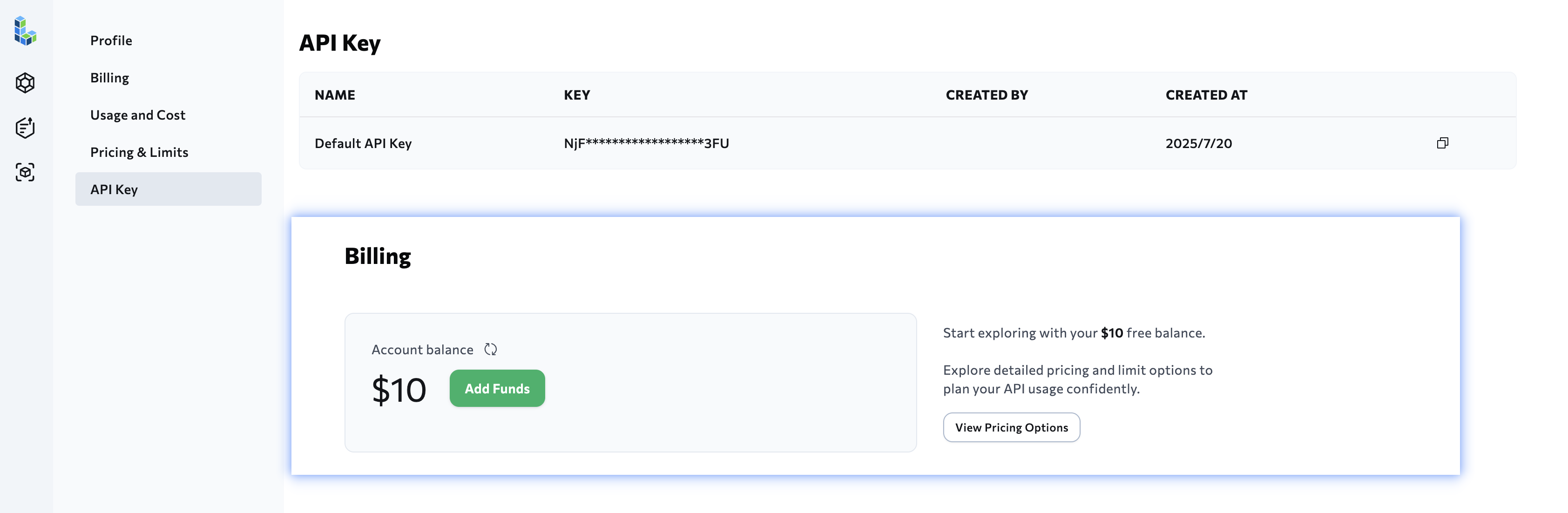
获取密钥后,将其设置为环境变量
$ export VISION_AGENT_API_KEY=<your-api-key>
或将其放入.env文件中
VISION_AGENT_API_KEY=<your-api-key>
# 8.2.2 文档的解析效果
从多个文档中提取数据:
# -*- coding: utf-8 -*-
from agentic_doc.parse import parse
# Parse multiple local files
file_paths = ["./alphafold3.pdf", "./yolov9.pdf"]
results = parse(file_paths)
for result in results:
print(result.markdown)
# Parse and save results to a directory
results = parse(file_paths, result_save_dir="./results")
result_paths = []
for result in results:
result_paths.append(result.result_path)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
提取了两篇论文的内容(合计42页),用掉了$2.52的赠送额度,处理速度还比较快。
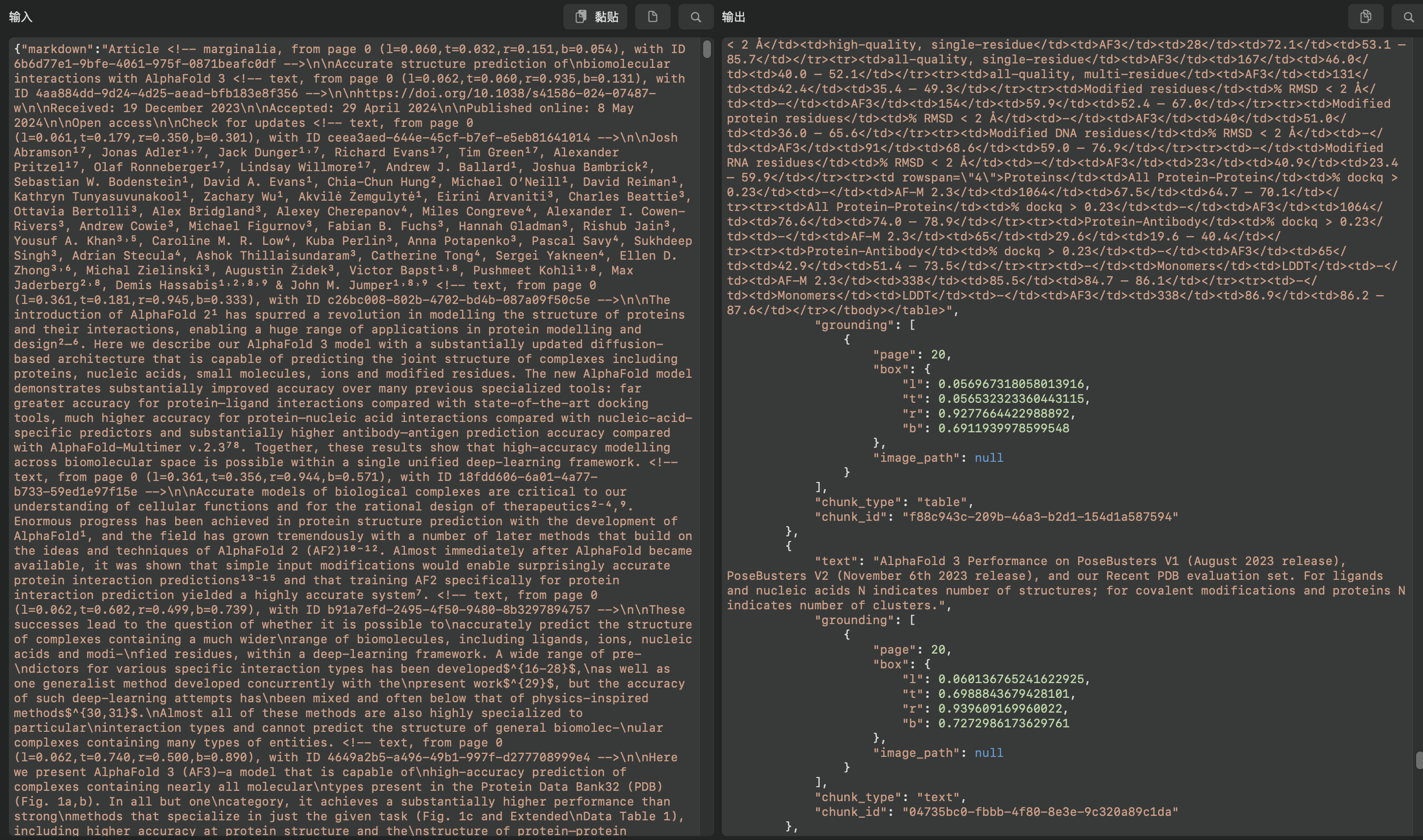
处理后的输出结果为JSON,里面包含完整的全文Markdown和切片结果,效果看起来还不错。
# 9. 参考资料
[1] DeepDoc深度文档理解 from Github (opens new window)
[2] cannot import name 'cached_property' from 'nougat.utils' from Github issues (opens new window)
[3] RAG优化: 非结构化文档解析方案汇总 from 知乎 (opens new window)
[4] MinerU vs DeepDoc:集成方案+图片显示优化 from 微信公众号 (opens new window)
[5] 分享一个较好的PDF内容抽取开源项目:PDF-Extract-Kit from 知乎 (opens new window)
[6] PDF-Extract-Kit的Linux的安装教程 from Github issues (opens new window)
[7] PDF-Extract-Kit下载模型文件 from Github (opens new window)
[8] 在 macOS 上使用 PDF-Extract-Kit from Github (opens new window)
[9] 基于MinerU的PDF解析API,支持一键启动 from 微信公众号 (opens new window)
[10] 基于MinerU的PDF解析API from Github (opens new window)
[11] Alibaba出品:OmniParser通用文档复杂场景下OCR抽取 from 微信公众号 (opens new window)
[12] DocLayout-YOLO,让多样性文档布局检测更快、更准、更强 from 微信公众号 (opens new window)
[13] MarkItDown深入研究 from Software 2.0 (opens new window)
[14] TableGPT2开源,复杂表格理解不存在了 from 微信公众号 (opens new window)
[15] PDF文档解析:从挑战到实践的简明指南 from 百度智能云 (opens new window)
[16] RAGflow分片策略与文档解析器 from 微信公众号 (opens new window)
[17] 字节开源高精度文档解析大模型Dolphin from 微信公众号 (opens new window)
[18] 一站式PDF解析神器!统一封装Docling、PyMuPDF、LlamaParse from 微信公众号 (opens new window)
[19] 字节开源文档解析Dolphin,PDF解析效率提升83%,到底行不行?from 微信公众号 (opens new window)
[20] MinerU v1.3.12:支持ppocrv5模型 from 微信公众号 (opens new window)
[21] 深入拆解 MinerU 解析处理流程 from 微信公众号 (opens new window)
[22] KonwFlow v0.0.5 发布:新增 Markdown 智能分块和按标题分块策略,检索效果提升明显 from 微信公众号 (opens new window)
[23] 3B小模型吊打72B巨头!轻量级文档解析OCR,性能超Gemini,高效且精准!from 微信公众号 (opens new window)
[24] RAG工具箱:基于多模态大模型的文档解析方案(2025版)from 知乎 (opens new window)
[25] 从复杂文档提取结构化数据:支持长文档与批量并行处理 from 微信公众号 (opens new window)