DeepReaserch智能体技术概述与实践
# 1. DeepReaserch基本介绍
# 1.1 DeepResearch基本概念
根据论文的定义,DeepReaserch 智能体是:
由大型语言模型驱动,为完成信息研究任务,集成了动态推理、自适应规划、多轮外部数据检索与工具使用,并能生成综合性分析报告的 AI 智能体。
简而言之,DeepReaserch 智能体以 LLM 为“大脑”,通过浏览器或API等方式实时获取外部知识,并能动态调用代码解释器、数据分析等工具,从而自主完成从提出研究计划到生成最终报告的端到端复杂研究流程。
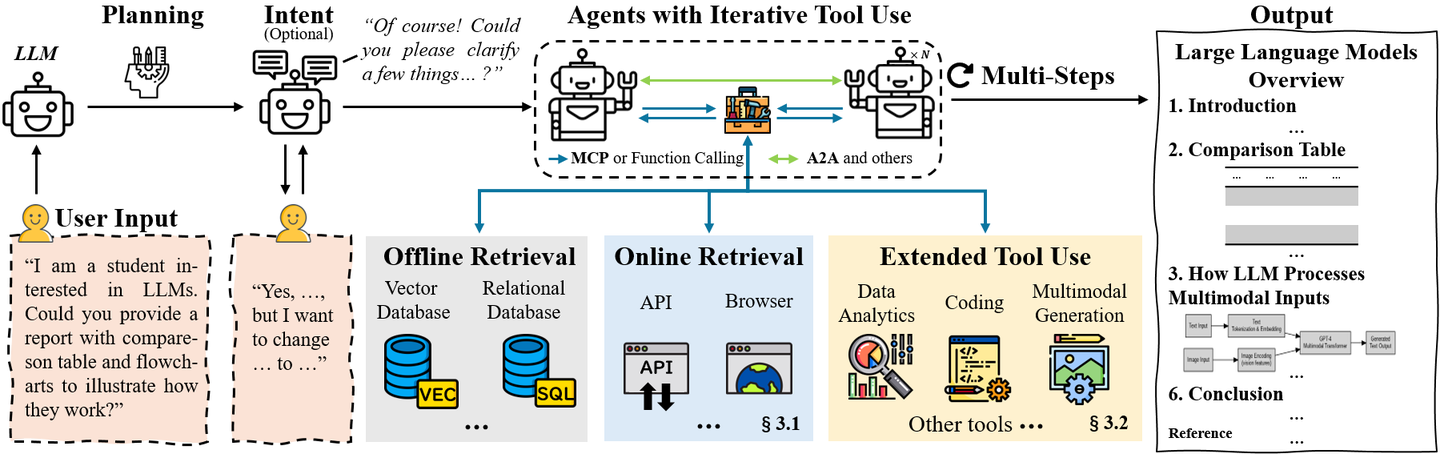
与传统技术相比,DeepReaserch 智能体的优势在于:
- 相较于 RAG:传统的 RAG 主要用于提升回答的事实准确性,但缺乏持续的、深入的推理能力。DeepReaserch 智能体不仅能够检索信息,还能对信息进行多步推理、规划和整合。
- 相较于工具调用:传统工具调用严重依赖预定义的工作流,灵活性差。DeepReaserch 智能体则具备动态规划和自适应交互能力,能够应对复杂多变的研究场景。
# 1.2 DeepResearch发展趋势
近年来,随着 LLM 的飞速发展,一类新型的自主 AI 系统——DeepReaserch 智能体应运而生。这些智能体旨在解决复杂、多轮的信息研究任务,它们集成了动态推理、自适应规划、多跳信息检索、迭代式工具使用和结构化报告生成等多种高级能力。
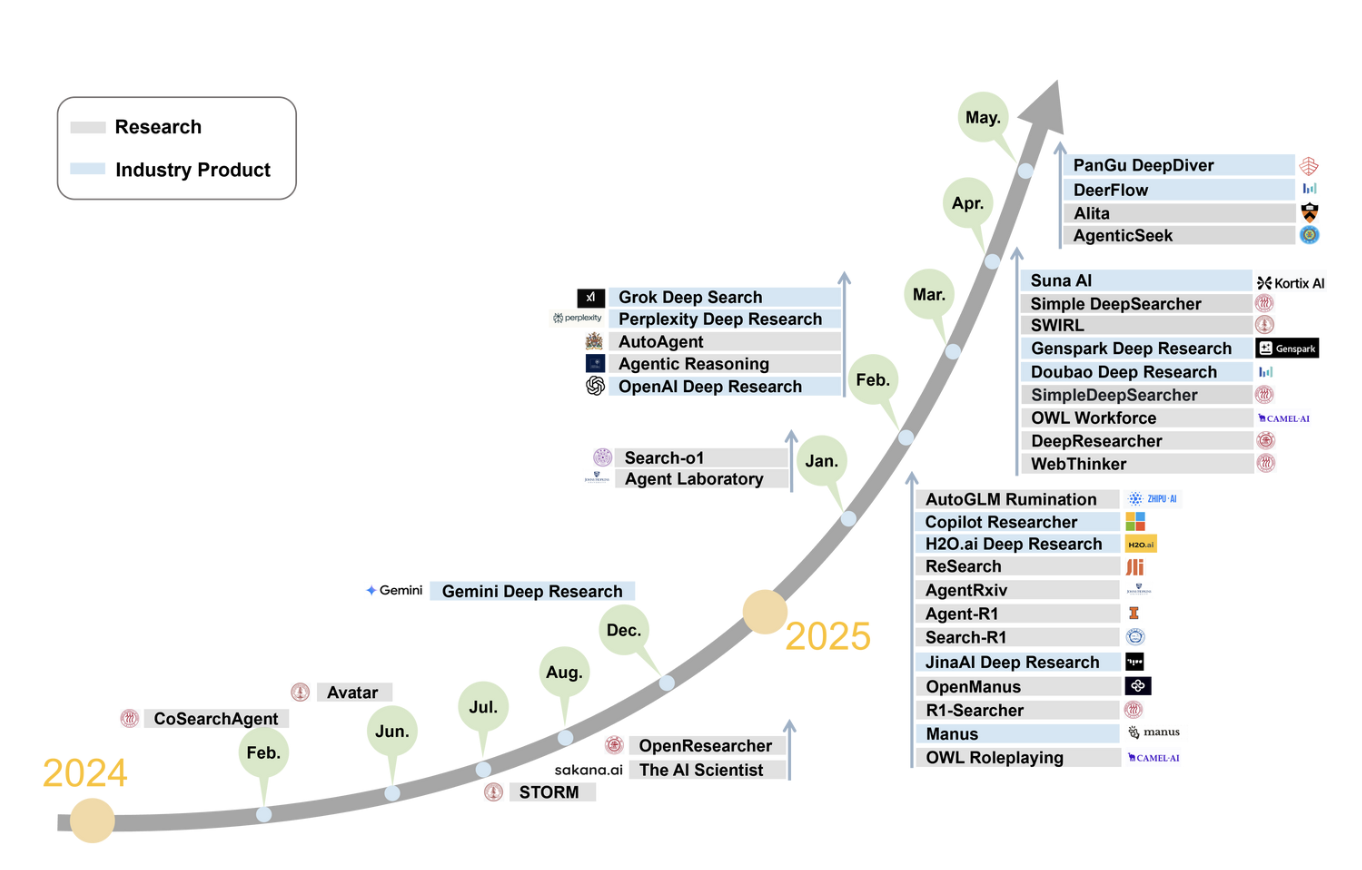
# 1.2.1 流行的DeepReaserch
各大科技公司纷纷布局 DeepReaserch 领域,推出了一系列标杆性产品。
- OpenAI Deep Research:采用单智能体架构,以 RL 优化的 o3 模型为核心。特点是交互式意图澄清、动态自适应研究流和全面的工具链集成。
- Gemini Deep Research:基于 Gemini 2.0 Flash 模型,同样采用 RL 优化的单智能体架构。其优势在于交互式研究规划、异步任务管理和高速自适应检索。
- Perplexity Deep Research:擅长将复杂问题分解为子任务,并进行迭代式搜索。其核心技术是迭代式信息检索和动态提示引导的模型选择。
- Grok DeepSearch:由 xAI 开发,结合实时信息检索和多模态推理。亮点是分段式模块处理流水线(包含信誉度评估)和动态资源分配。
- Microsoft Copilot Researcher and Analyst:Researcher 专注于复杂研究任务,Analyst 则是一个高级数据分析智能体。它们能安全地访问用户工作数据和网络信息,提供专家级知识。
# 1.2.2 OpenAI的DeepResearch
Deep Research 是一个利用推理能力综合大量联网信息并为你完成多步骤研究任务的 Agent,它能在几十分钟内完成人类需要数小时才能完成的工作。它的背后是一个定制化的o3模型,该模型针对网页浏览和 Python 数据分析进行了优化,能够利用推理能力搜索、解读和分析互联网上的大量文本、图像和 PDF 文件来生成研究报告。
- 在一系列针对现实问题的公开评估测试中,Deep Research达到了SOTA,其中在Humanity's Last Exam上准确率为26.6%,超过了DeepSeek-R1(9.4%)和o3-mini high(13.0%),在GAIA上达到了72.57,超过之前最好的方法(63.64)。
- 目前的Deep Research也有局限性,比如会在回答中生成虚假信息或做出错误推断,而且可能难以区分权威信息与谣言,而且任务启动时间较长。它的推理成本很高,目前只对ChatGPT Pro用户开放,且每月最多支持100次查询,后续会逐步开放。
官方介绍:https://openai.com/index/introducing-deep-research (opens new window)

Deep Research vs GPT-4o:
| 功能 | GPT-4o | Deep Research |
|---|---|---|
| 任务类型 | 通用对话 | 深度研究 |
| 信息获取 | 主要为训练数据 | 实时联网搜索 |
| 报告级别 | 快速总结 | 专业级研究报告 |
| 引用来源 | 仅搜索任务有 | 清晰引用、可验证 |
Deep Research使用示例如下:

# 1.3 DeepResearch应用场景
DeepResearch 在多个领域的展现出巨大潜力:
- 学术研究:辅助研究人员提供文献综述与综合、假设生成与验证、跨学科研究支持,从而提高研究效率。
- 科学发现:协助科研人员进行数据分析与模式识别、实验设计与仿真、科学文献整合和自主科学发现,加速科学发现与技术创新。
- 商业智能:进行市场调研和竞争分析,生成战略决策支持报告,优化业务流程,帮助公司做出更精准的商业决策,提升运营效率。
- 金融分析:进行投资研究与尽职调查、财务趋势分析、风险评估与建模等,帮助做出更明智的投资决策。
- 教育应用:提供个性化学习支持、教育内容开发和学术研究培训等,提供灵活、高效的研究和培养双模式。
- 个人知识管理:实现个人信息组织与管理、个人学习与发展、个人用户的决策支持等,增强个人信息组织和利用。
# 2. DeepReaserch关键技术
# 2.1 核心技术组件
# 2.1.1 信息获取
为了获取最新、最全面的信息,DeepResearch 智能体需要与外部世界交互,主要通过2种方式集成搜索引擎。
[1] 基于 API 的搜索引擎
特点:通过调用搜索引擎或专业数据库(如 arXiv、PubMed)的 API 来获取信息。这种方式速度快、效率高、返回的数据结构化,且易于扩展。
案例:
- Gemini DR 利用 Google Search API 和 arXiv API 进行大规模网页检索。
- Grok DeepSearch 通过新闻源、维基百科 API 和 X 的原生接口持续索引信息,确保知识的实时性。
- AI Scientist 调用 Semantic Scholar API 来验证研究创意的创新性。
局限:难以处理需要用户交互、JavaScript 动态渲染或登录验证的网页内容。
[2] 基于浏览器的搜索引擎
特点:通过模拟人类在浏览器中的交互行为(如点击、滚动、填写表单)来获取信息。这种方式灵活、功能强大,能访问动态和非结构化的多模态内容。
案例:
Manus AI 为每个研究会话运行一个沙盒化的 Chromium 实例,可编程地执行浏览、点击、滚动和下载等操作。
AutoAgent 在 BrowserGym 环境中运行,能够与页面组件交互并下载文件。
DeepResearcher 拥有一个专门的网页浏览智能体,能分段处理网页并增量聚合相关信息。
局限:延迟较高、资源消耗大,且处理不同网页的布局和错误时更为复杂。
实践中,许多先进的 DeepResearch 智能体采用混合架构,结合 API 的高效和浏览器的全面性,以实现最佳的信息获取效果。
# 2.1.2 工具使用
为了处理复杂的研究任务,DeepResearch 智能体需要超越简单的信息检索,集成多种外部工具。核心工具模块包括:
- 代码解释器:允许智能体在推理过程中执行代码(通常是 Python),用于数据处理、算法验证和模型仿真。
- 数据分析:将原始数据转化为结构化洞见,例如计算统计数据、生成图表和进行量化评估。
- 多模态处理与生成:集成和分析文本、图像、音视频等异构数据,并生成多模态报告,丰富了智能体的理解和表达能力。
| DeepResearch Agent | Code Interpreter | Data Analytics | Multimodal |
|---|---|---|---|
| CoSearchAgent | ❌ | ✅ | ❌ |
| Storm | ✅ | ❌ | ❌ |
| The AI Scientist | ✅ | ✅ | ❌ |
| AutoAgent | ✅ | ✅ | ✅ |
| Grok DeepSearch | ✅ | ✅ | ✅ |
| OpenAI DR | ✅ | ✅ | ✅ |
| Gemini DR | ✅ | ✅ | ✅ |
| Manus | ✅ | ✅ | ✅ |
| OWL | ✅ | ✅ | ✅ |
# 2.1.3 记忆机制
DeepResearch 过程会产生海量信息(可能多达数百万 Token),远超当前 LLM 的上下文窗口限制。为了解决这个问题,DeepResearch 系统采用了3种优化策略:
- 扩展上下文窗口长度:最直接的方法,如 Google Gemini 模型支持高达一百万 Token 的上下文窗口。但这种方法计算成本高昂。
- 压缩中间步骤:通过总结或压缩中间推理结果来减少 Token 数量。如 The AI Scientist 在不同工作流阶段间传递摘要信息;Search-o1 提出的“文档中推理”概念利用 LRM 压缩文档,提升效率。但这种方法可能导致细节信息丢失。
- 利用外部结构化存储:将历史信息存储在外部文件系统或数据库中,实现持久化和高效检索。
# 2.2 架构实现模式
Deep Research的基础架构模式包含:单体式、流水线式、多智能体式和混合式。
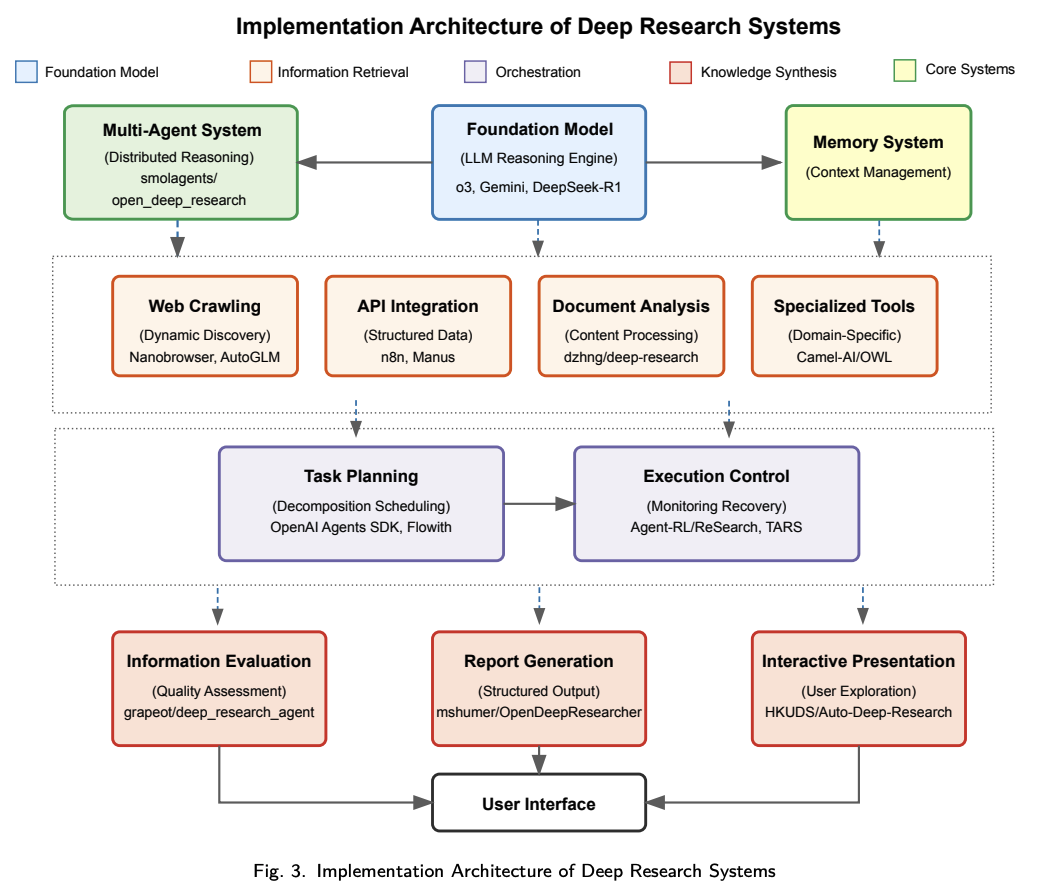
# 2.2.1 单体式架构模式
单体实现将所有Deep Research能力集成于以核心推理引擎为中心的统一架构中。单体式架构如下图所示,这类系统采用集中控制机制,直接集成各专用模块。
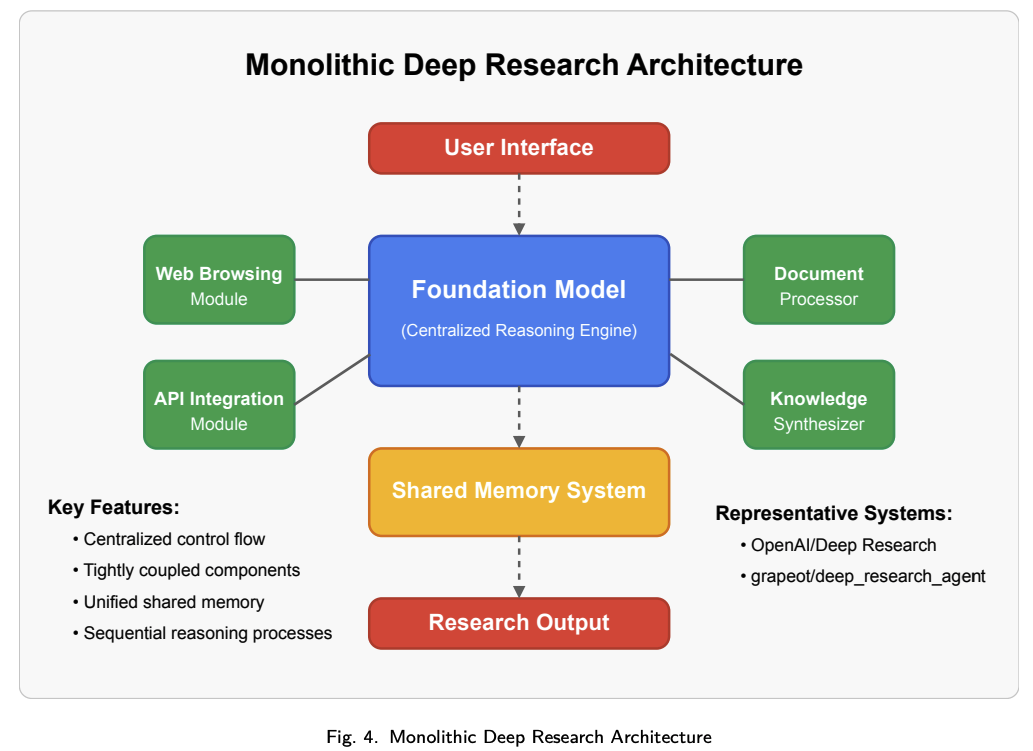
该模式的主要特征包括:
- 集中式控制流:所有操作均通过主推理引擎进行路由,统一管理全局状态与执行上下文。
- 耦合集成:各专用模块(如网页浏览、文档处理等)直接和中央控制器集成。
- 共享内存架构:信息状态保存在中央存储器系统中,所有组件均可访问。
- 顺序推理流程:操作通常按中央控制器定义的结构化顺序进行。
该模式通过统一控制结构确保推理连贯性和一致性,但在可扩展性和并行化复杂操作方面存在挑战。代表性的实现有OpenAI/DeepResearch和grapeot/deep_research_agent,展示了该架构如何在保持实现简单性的同时,跨不同的信息源实现一致性推理。
# 2.2.2 流水线架构模式
流水线架构通过一系列专用处理阶段串联实现深度研究能力,每个阶段通过定义明确的接口相互连接。流水线式架构如下图所示,系统将研究工作流分解为独立处理组件,各阶段间有明确的数据转换。
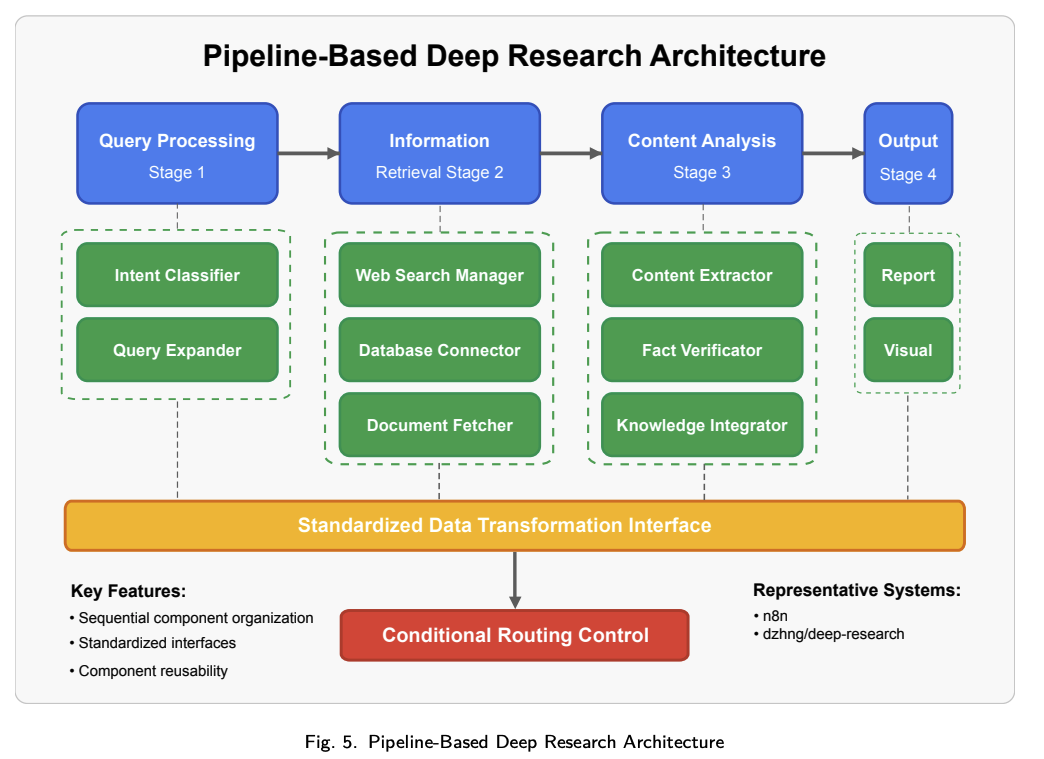
该模式的主要特征包括:
- 顺序组件组织:研究任务通过预定义的专用模块顺序流转。
- 标准化接口:各阶段之间明确定义数据转换规范,便于模块化替换。
- 分阶段处理逻辑:每个模块仅实现特定转换,对全局状态依赖最小。
- 可配置工作流路径:高级实现允许根据中间结果在不同的处理路径之间进行条件路由。
流水线架构在工作流定制和组件复用性上表现突出,但对需跨组件反复优化的复杂推理任务不够友好。代表性的实现包含n8n和dzhng/deep-research等系统,展示了如何通过明确流程实现复杂的自动化研究。
# 2.2.3 多智能体架构模式
多智能体架构通过一组专用自主智能体间的协作实现深度研究能力。多智能体架构如下图所示,系统将研究工作分配给不同角色和职责的智能体,然后通过它们之间的协作完成研究任务。
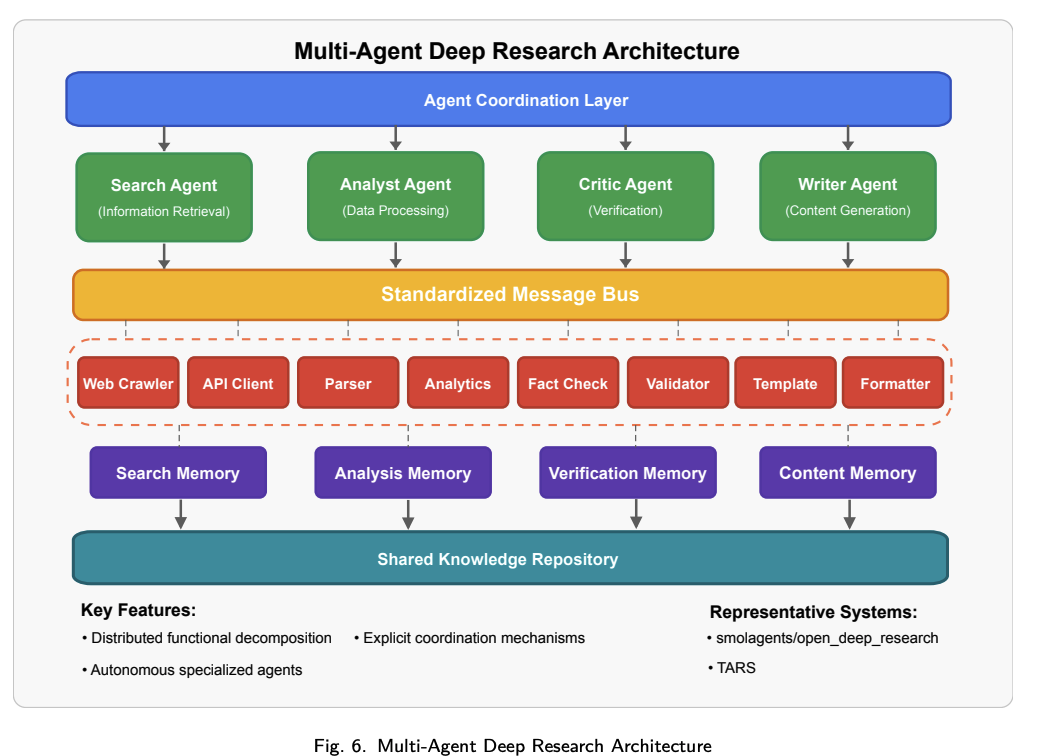
该模式的主要特征包括:
- 分布式功能分解:研究能力分配给具有明确角色定义(检索员、分析师、评审员等)的专业智能体。
- 显式协调机制:标准化的消息传递和任务分派协议实现智能体间协作。
- 自主决策逻辑:各智能体在指定领域内具独立推理能力。
- 动态任务分配:支持基于智能体能力和当前工作负载进行灵活的任务分配。
多智能体架构在需要多样化专业能力和并行处理的复杂研究任务中表现出色。其分布式特性使其能够为复杂研究工作流提供卓越的扩展性,但同时也带来了跨智能体保持整体一致性和连贯推理的挑战。代表实现有smolagents/open_deep_research和TARS,展现了多智能体如何通过专业化协作实现复杂研究工作流。
# 2.2.4 混合架构模式
混合架构融合了多种架构模式的优势,以应对不同研究需求。混合架构如下图所示,系统通过战略性整合架构方法,以满足特定的研究需求。
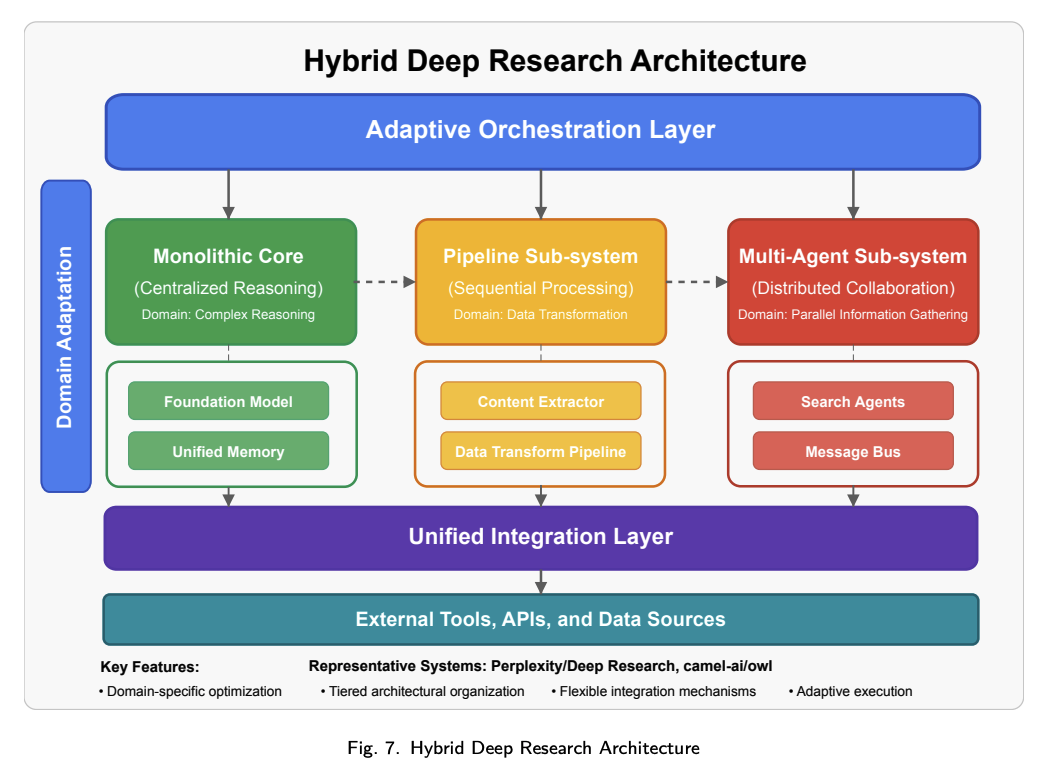
该模式的主要特征包括:
- 分层架构组织:根据功能需求,在不同的系统层级采用不同的架构模式。
- 领域特定优化:根据特定领域的处理需求选择架构方法。
- 集成机制灵活:采用标准化接口,使得采用不同架构模式的组件之间能够通信。
- 自适应执行框架:控制机制根据任务特征动态调整处理方法。
混合架构提供了卓越的灵活性和优化机会,但也带来了实现复杂性与集成难题。代表实现有Perplexity/DeepResearch和Camel-AI/OWL,其将集中式推理与分布式信息收集及专用处理流水线结合,实现了兼顾性能与能力的复杂研究。
# 2.2.5 架构模式对比
除上述核心架构模式外,Deep Research 生态也被提供标准化组件的智能体框架(如 LangGraph、Google Agent Development Kit、CrewAI 等)大幅扩展。这些框架提供了不同的智能体编排、执行控制和推理编排方法,适合既需要深度,也需要广度的复杂研究任务。
如下表,总结了各架构模式在关键性能维度上的对比。

每种架构模式均有独特优势与局限,影响其在特定深度研究应用中的适用性。
- 单体式:在推理连贯性和实现简单性方面表现出色,其适用于工作流明确的研究应用。
- 流水线式:提供卓越的可扩展性和组件重用性,通过模块化组合支持定制化研究工作流。
- 多智能体式:提供卓越的并行化处理和容错能力,支持需要多样化专业能力的复杂研究任务。
- 混合式:通过战略整合平衡上述特性,为多样化的研究需求提供灵活的优化方案。
架构选择决定了系统能力、性能与应用的适配性。随着生态的持续演进,预计将有更多创新架构融合基础模式以应对新兴需求。
# 3. DeepReaserch效果评估
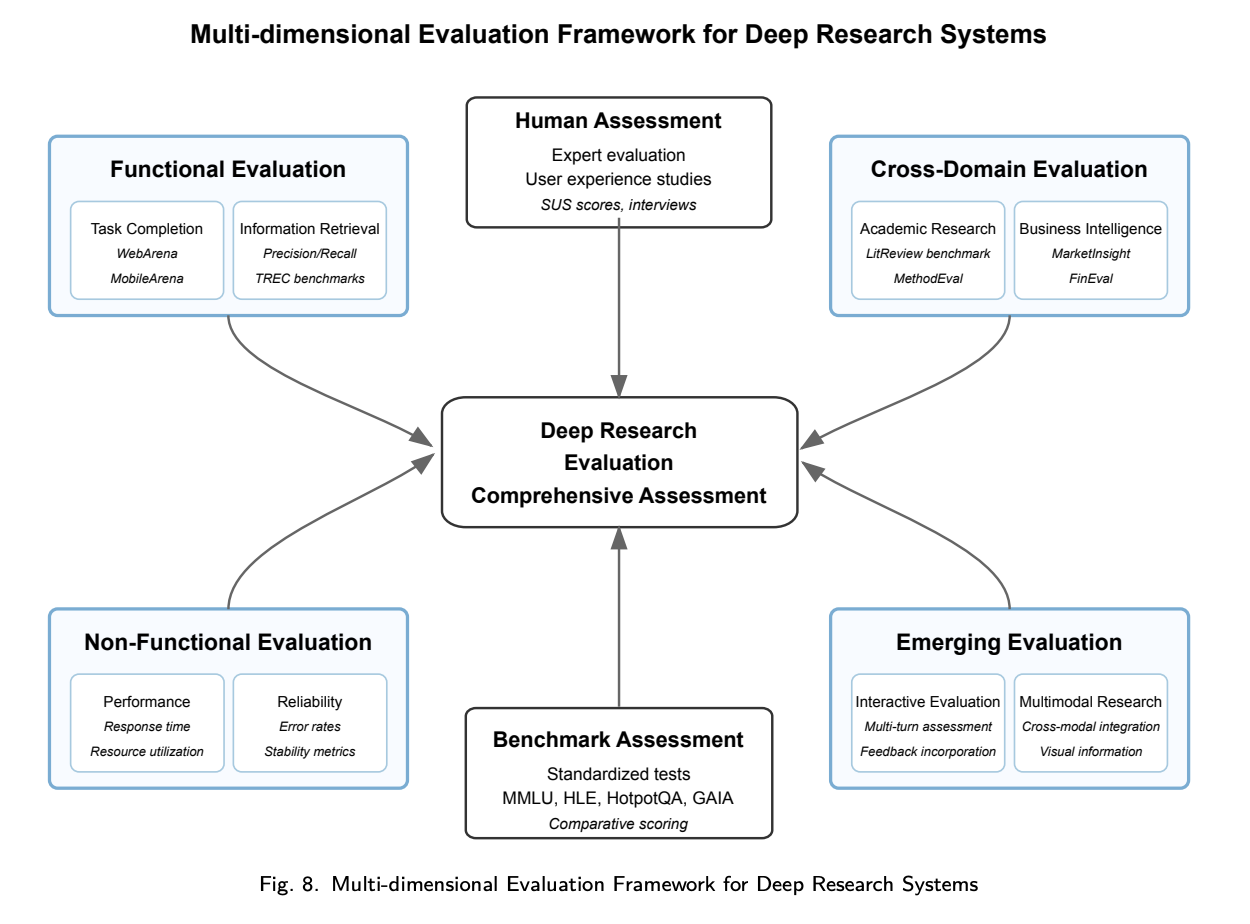
# 3.1 功能性评估框架
# 3.1.1 任务完成能力评估
- 任务成功率指标:任务完成的量化评估为性能提供了客观度量。例如WebArena可用于衡量基于网页的研究任务的完成率。
- 多次尝试解决率:有效的研究往往需要多次尝试和迭代改进,该指标的引入用于评估系统的弹性和适应性。
# 3.1.2 信息检索质量评估
- 搜索有效性指标:信息检索的质量能显著影响研究的表现,该评估采用的指标如准确率、召回率和F1分数(平衡指标)。例如TREC可为搜索有效性提供了标准化评测。
- 信息源多样性评估:全面的研究需要来着多源视角的信息,通过引入该指标,来衡量信息的利用广度。
# 3.1.3 知识综合准确性评估
- 事实一致性指标:该指标用于评估生成内容和原始信息的一致性。在知识综合过程中,为避免引入错误或失真,需要采用事实核查技术,将生成内容和原始信息对比,识别潜在不准确或者无依据内容。例如TruthfulQA可用于评估语言模型的真实性。
- 逻辑一致性评估:在知识综合时,要求报告需要具备逻辑严密性和连贯性。其评估方法采用推理有效性进行评估,检验研究成果中的逻辑结构和推理模式。这一维度对自动化评估尤具挑战,通常需人工专家评估以保证可靠性。
# 3.2 非功能性评估指标
# 3.2.1 性能与效率指标
- 响应时间分析:及时性是研究结果的输出的重要维度,主要评估指标包括响应时间指标,衡量标准任务的完成时长等。
- 资源利用率评估:资源利用率有助于更广泛的部署和访问,全面评估包括内存占用、计算戏曲和能耗等资源指标。例如专门的测试基准Minerva可以评估LLM的可编程内存能力,并提供其在处理长上下文信息方面的效率评估结果。
# 3.2.2 可靠性与稳定性指标
- 错误率分析:用于衡量在各种场景下失败的频率。研究结果的可靠性会直接影响用户信任和采纳,商用系统通常错误率较低,但在复杂或新颖任务下仍有挑战。专业可靠性测试采用对抗场景触发错误模式,洞见系统鲁棒性。例如OpenAI/DeepResearch与Agent-RL/ReSearch等系统内置错误恢复机制,提升了在挑战情境下的可靠性,凸显弹性对实际研究的重要性。
- 长期稳定性评估:用于衡量在不同部署环境和基础设施下的稳定性。全面的评估包含衡量长时间会话和重复执行过程中性能的一致性等稳定性指标。该维度对于需要适配不同部署环境和基础设施的开源产品尤为重要。
# 3.2.3 用户体验与可用性指标
- 界面可用性评估:直观界面提升系统可达性和有效利用。可用性评估采用系统可用性量表(SUS)和任务完成时间等标准化指标。
- 学习曲线评估:新用户易上手性显著影响采纳和有效利用。评估包括学习曲线指标,衡量不同技术背景用户达到熟练所需时间。
# 3.3 跨领域评测基准
# 3.3.1 学术研究任务基准
- 文献综述基准:全面文献综合是学术研究的基本任务,需复杂的信息检索、批判性分析和综合能力。目前尚无专门评估系统跨科学领域识别文献、综合要点与发现研究空白的基准套件。建议采用Nature Reviews等高水平综述作为标准,学术知识图谱中的引文网络可作为补充,通过衡量系统遍历引文关系和识别核心文献的能力来评估。
- 方法论评估基准:对研究方法的批判性评估需复杂分析能力,目前尚无用于方法论的评估基准。有效的基准可能包含多层评估标准:可复现性、混杂变量识别、统计功效分析以及不确定性处理的能力。
# 3.3.2 商业分析任务基准
- 市场分析基准:了解市场动态,分析竞争格局、识别市场趋势并基于多源信息生成决策建议。
- 财务分析基准:结合定量推理结合对市场动态的理解。例如FinEval基准为分析财报、评估投资机会和风险因素提供了标准化框架。
# 3.3.3 通用知识管理基准
- 事实研究基准:准确的信息收集是有效研究的基础。例如SimpleQA基准评测了模型对短、唯一答案的事实问题的解答能力。
- 人文与社会科学基准:全面评估需涵盖STEM之外的领域。MMLU基准评估系统在人文与社科研究任务上的表现,包括历史分析、伦理评估和社会趋势识别。
# 3.4 新兴评估方法
- 交互式评估框架:传统静态基准难以反映实际研究流程的动态与交互性。因此,需要交互式框架以评测AI系统多轮互动优化研究策略的能力。例如QuestBench专门考察AI识别信息缺失并提出澄清问题的能力。
- 多模态研究评估:多模态内容是深度研究关键能力之一,先进的评估框架需要引入多模态评测,考察系统综合文本、图像、数据可视化和结构化内容的能力。
- 伦理与偏见评估:全面的评估越来越多的将伦理意识、偏见检测和信息处理公平性等指标纳入其中。
# 4. DeepReaserch开源实践
# 4.1 Open-Deep-Research
# 4.1.1 Open-Deep-Research简介
一个基于AI的研究助手,通过结合搜索引擎、网页爬取和大语言模型,实现迭代式的深度研究,能够不断优化研究方向并深入探索主题,目标是提供最简洁的深度研究智能体实现。
功能特性:
- 迭代式研究:通过不断生成搜索查询、处理结果,并基于发现深入探索,实现深度研究。
- 智能查询生成:利用大语言模型(LLM)根据研究目标和已有发现生成有针对性的搜索查询。
- 深度与广度控制:支持配置参数,灵活控制研究的广度(breadth)和深度(depth)。
- 智能追问:自动生成后续问题,更好地理解研究需求。
- 综合报告:输出带有研究结论和来源的详细 Markdown 报告。
- 并行处理:可并发执行多个搜索与结果处理任务,提高研究效率。
# 4.1.2 Open-Deep-Research原理
用户给定研究深度和广度 → 系统自动生成并迭代查询 → 不断吸收新信息并延伸问题 → 最终产出完整的 Markdown 报告
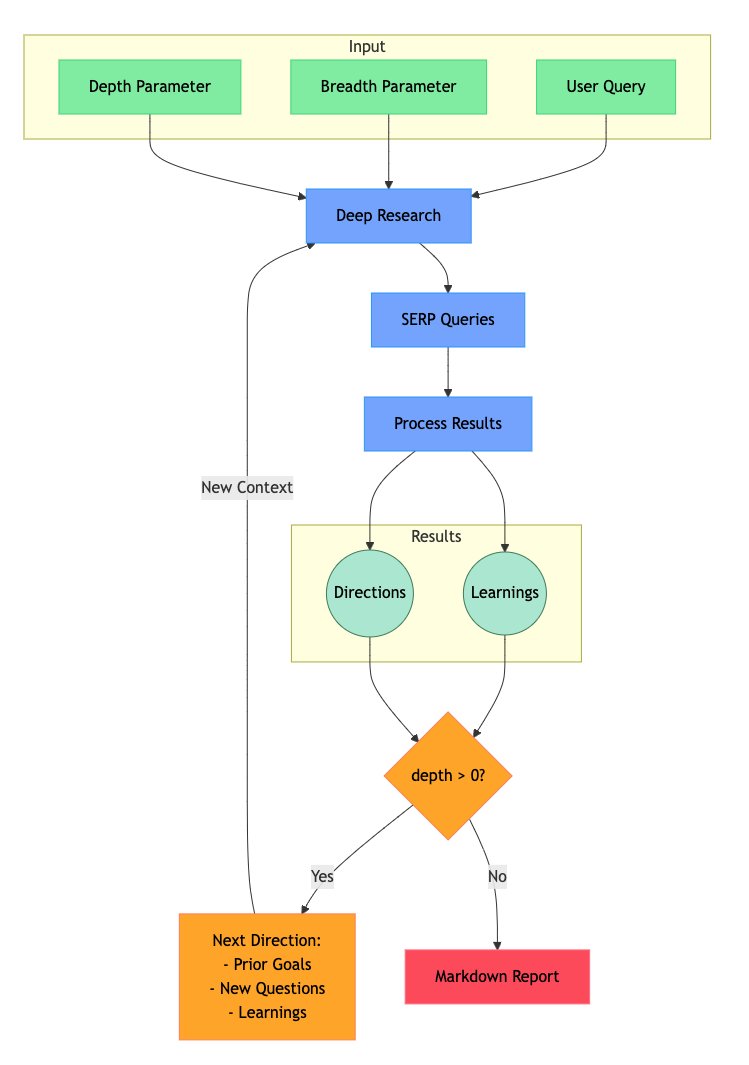
[1] 输入阶段:用户提供三个关键输入
- Depth Parameter(深度参数):决定研究向下探究的层数,即迭代次数。
- Breadth Parameter(广度参数):决定研究时在同一层会发散多少个方向。
- User Query(用户查询):研究的起点问题。
[2] 研究执行
- 系统根据输入参数启动 Deep Research(深度研究),并生成 SERP Queries(搜索引擎查询)。
- 对搜索结果进行 Process Results(结果处理),提炼出关键信息。
[3] 结果归纳:结果被组织为两类
- Directions(研究方向):未来可能进一步探索的问题或线索。
- Learnings(研究结论):已经得到的知识点和洞察。
[4] 判断是否继续:系统检查 depth > 0
- Yes:如果深度参数仍大于 0,就会结合先前目标、新问题和已有学习,生成新的研究方向,继续迭代循环。
- No:如果深度已经用尽,就停止迭代,进入最终输出阶段。
[5] 输出阶段
- 当迭代完成后,所有结果会被整理成一个 Markdown Report,其中包含研究的过程、方向和最终结论。
# 4.2 Firecrawl网页解析提取
# 4.2.1 Firecrawl项目简介
Firecrawl 是一款开源 AI 爬虫工具,可高效提取网页数据并转换为 Markdown 或结构化格式。其核心亮点是 LLM Extract,借助大语言模型快速解析网页内容,生成适配大模型应用的 LLM-ready 数据。
- 项目地址:https://github.com/firecrawl/firecrawl (opens new window)
- 官方文档:https://docs.firecrawl.dev/introduction
- 试用地址:https://www.firecrawl.dev (opens new window)
- 私有部署:https://docs.firecrawl.dev/contributing/self-host (opens new window)
主要功能:
- 网页爬取(Crawl):给Firecrawl一个URL,它就能自动爬取这个网站的所有可访问子页面,不需要站点地图。无论是静态页面还是动态渲染的单页应用,它都能搞定。
- 内容提取(Scrape):不仅能抓网页,还能提取指定内容,比如文章正文、产品信息,甚至可以按照要求返回Markdown、HTML或结构化数据。
- 动态交互支持:Firecrawl支持模拟用户操作,比如点击、输入、滚动等,特别适合抓取需要交互才能加载内容的网页。
- 批量处理与搜索:支持批量抓取多个URL,还能结合网页搜索功能,帮你从搜索结果中提取完整内容。
- 结构化数据提取(Extract):通过Prompt,Firecrawl能智能提取网页中的特定信息,比如“给我抓取所有产品的名称、价格和描述”。
Firecrawl 可以使用官方 API,有一定的免费试用额度可以用来测试。
# 4.2.2 Firecrawl私有部署
这里使用 Docker Compose 一键部署。由于我这里只用到检索功能,因此就不配置大模型了,直接使用默认的 .env 文件。
$ git clone https://github.com/firecrawl/firecrawl.git
$ cd firecrawl
$ touch .env
# ===== Required ENVS ======
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
#for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
REDIS_URL=redis://redis:6379
#for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
## To turn on DB authentication, you need to set up supabase.
USE_DB_AUTHENTICATION=false
# ===== Optional ENVS ======
# Supabase Setup (used to support DB authentication, advanced logging, etc.)
SUPABASE_ANON_TOKEN=
SUPABASE_URL=
SUPABASE_SERVICE_TOKEN=
# Other Optionals
# use if you've set up authentication and want to test with a real API key
TEST_API_KEY=
# set if you'd like to test the scraping rate limit
RATE_LIMIT_TEST_API_KEY_SCRAPE=
# set if you'd like to test the crawling rate limit
RATE_LIMIT_TEST_API_KEY_CRAWL=
# add for LLM dependednt features (image alt generation, etc.)
OPENAI_API_KEY=
BULL_AUTH_KEY=@
# use if you're configuring basic logging with logtail
LOGTAIL_KEY=
# set if you have a llamaparse key you'd like to use to parse pdfs
LLAMAPARSE_API_KEY=
# set if you'd like to send slack server health status messages
SLACK_WEBHOOK_URL=
# set if you'd like to send posthog events like job logs
POSTHOG_API_KEY=
# set if you'd like to send posthog events like job logs
POSTHOG_HOST=
# set if you'd like to use the fire engine closed beta
FIRE_ENGINE_BETA_URL=
# Proxy Settings for Playwright (Alternative you can can use a proxy service like oxylabs, which rotates IPs for you on every request)
PROXY_SERVER=
PROXY_USERNAME=
PROXY_PASSWORD=
# set if you'd like to block media requests to save proxy bandwidth
BLOCK_MEDIA=
# Set this to the URL of your webhook when using the self-hosted version of FireCrawl
SELF_HOSTED_WEBHOOK_URL=
# Resend API Key for transactional emails
RESEND_API_KEY=
# LOGGING_LEVEL determines the verbosity of logs that the system will output.
# Available levels are:
# NONE - No logs will be output.
# ERROR - For logging error messages that indicate a failure in a specific operation.
# WARN - For logging potentially harmful situations that are not necessarily errors.
# INFO - For logging informational messages that highlight the progress of the application.
# DEBUG - For logging detailed information on the flow through the system, primarily used for debugging.
# TRACE - For logging more detailed information than the DEBUG level.
# Set LOGGING_LEVEL to one of the above options to control logging output.
LOGGING_LEVEL=INFO
$ docker compose up -d
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 4.2.3 Firecrawl接口测试
更多示例详细见官方的README,部分任务需要配置LLM才可以使用。
// 创建爬取任务
$ curl -X POST http://127.0.0.1:3002/v2/crawl \
-H 'Content-Type: application/json' \
-d '{
"url": "https://www.imiao.top"
}'
{"success":true,"id":"d0437815-df53-4bd8-a1d9-a9da8b30ef46","url":"http://127.0.0.1:3002/v2/crawl/d0437815-df53-4bd8-a1d9-a9da8b30ef46"}
// 查看爬取结果
$ curl -X GET http://127.0.0.1:3002/v2/crawl/d0437815-df53-4bd8-a1d9-a9da8b30ef46 \
-H 'Content-Type: application/json'
// 获取网页地图
$ curl -X POST http://127.0.0.1:3002/v2/map \
-H 'Content-Type: application/json' \
-d '{
"url": "https://www.imiao.top"
}'
// 网络信息搜索
$ curl -X POST http://127.0.0.1:3002/v2/search \
-H "Content-Type: application/json" \
-d '{
"query": "deepseek原理",
"limit": 2,
"scrapeOptions": {
"formats": ["markdown", "links"]
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 4.3 Deep-Research-Web
# 4.3.1 Deep-Research-Web简介
Open-Deep-Research 的前端UI,其中包含一些改进和修复。它可以接入大模型,结合搜索引擎和网页抓取,对各种主题进行深入研究。
功能特性:
- 深度研究:通过多轮次的搜索和推理,逐步深入挖掘研究主题,自动扩展和细化问题,提供全面的研究结果。根据已获取的信息,AI 助手会实时调整搜索方向,确保研究的深度和广度。
- 搜索可视化:以树状图的形式展示研究过程,清晰呈现每个节点的搜索内容和推理逻辑,帮助用户追踪 AI 的研究路径。
- 节点信息管理:用户可以查看每个节点的详细内容,包括搜索结果、引用链接等,还可以对节点进行标记、删除或重新搜索。
- 联网搜索与信息检索:能实时访问网络,从互联网上检索相关的信息,包括文本、图像、PDF 文件等。通过智能搜索算法提高信息检索的效率和准确性,支持多种搜索服务,如 Tavily 和 Firecrawl。
- 数据分析与处理:检索到信息后,它会对数据进行分析和处理,提取关键信息和数据。能处理多模态数据,包括文本、图像和表格等,通过自定义算法解析和理解表格、图表中的数据,进行结构化处理。
- 报告生成与可视化:根据分析结果,它会生成一份详细的研究报告,包括清晰的引用和对其思考过程的总结。包含文本信息,图像、表格、图表等多种形式的内容。
# 4.3.2 Deep-Research-Web搭建
使用Docker进行一键部署,这里就不设置环境变量了,在页面的设置按钮处现配即可。
$ docker run -p 3000:3000 --name deep-research-web -d anotia/deep-research-web:latest
注:不需要再额外部署 Open-Deep-Research 项目了,虽然是基于它做的,但这里面已经集成了。
# 4.3.3 Deep-Research-Web使用
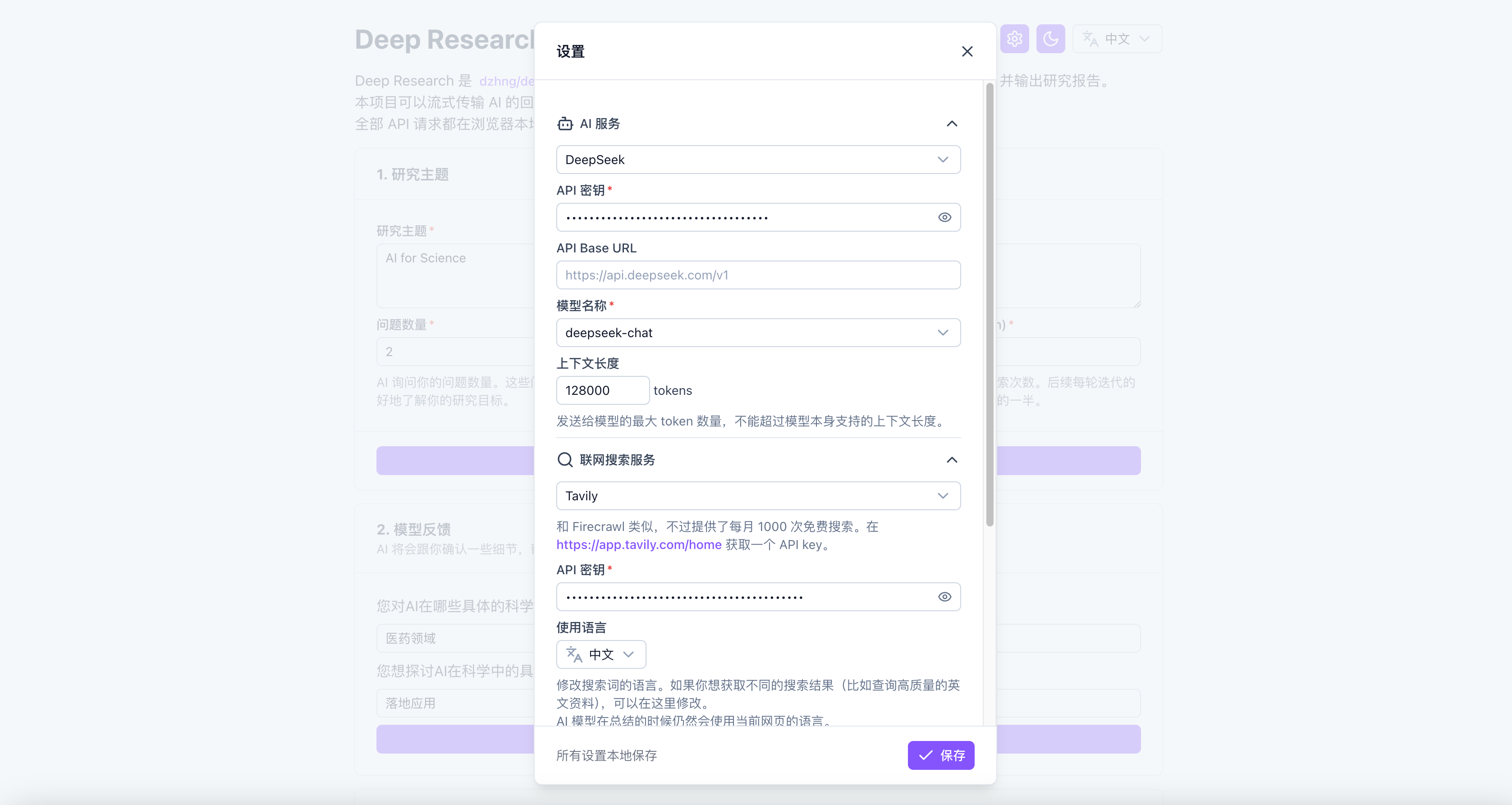
Step1:输入研究主题,并设置问题数量(“模型反馈”处会追问一些问题细节)、研究深度、研究广度
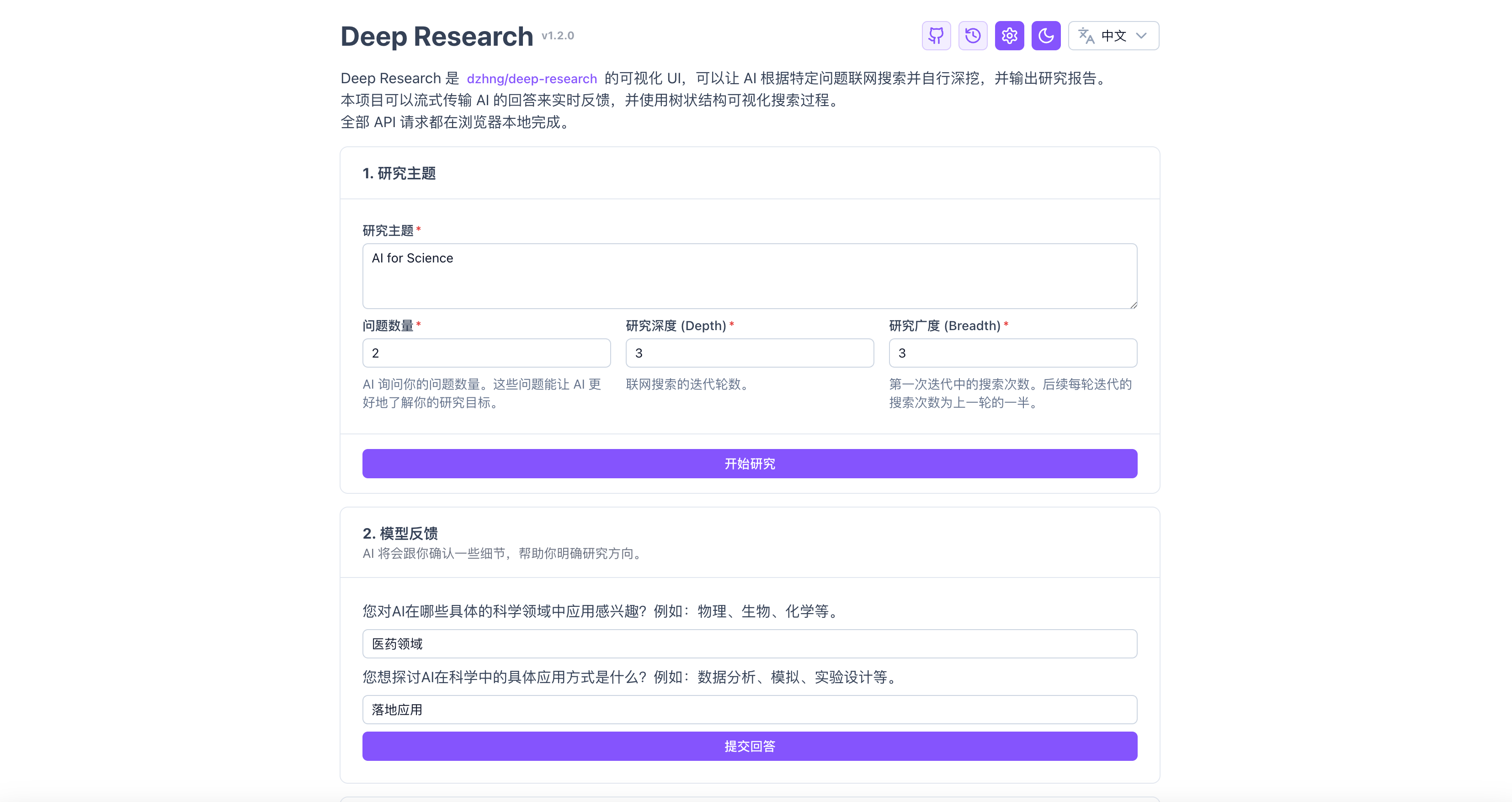
Step2:设置大模型服务与联网检索服务(支持Tavily、Firecrawl、Google PSE),使用商业API(有免费额度)或者自部署的均可。
注:我这里尝试过Tavily的商业API、Firecrawl自部署的API,均可成功运行,如果考虑速度的话,还是用商业API更好些。
Step3:以树状形式查看检索过程的每个节点,每个节点都有单独的研究目标、访问网址、结论。

Step4:全部节点检索完成后,可以对分节点的结论总结凝练,生成最终的研究报告,可以将其导出。
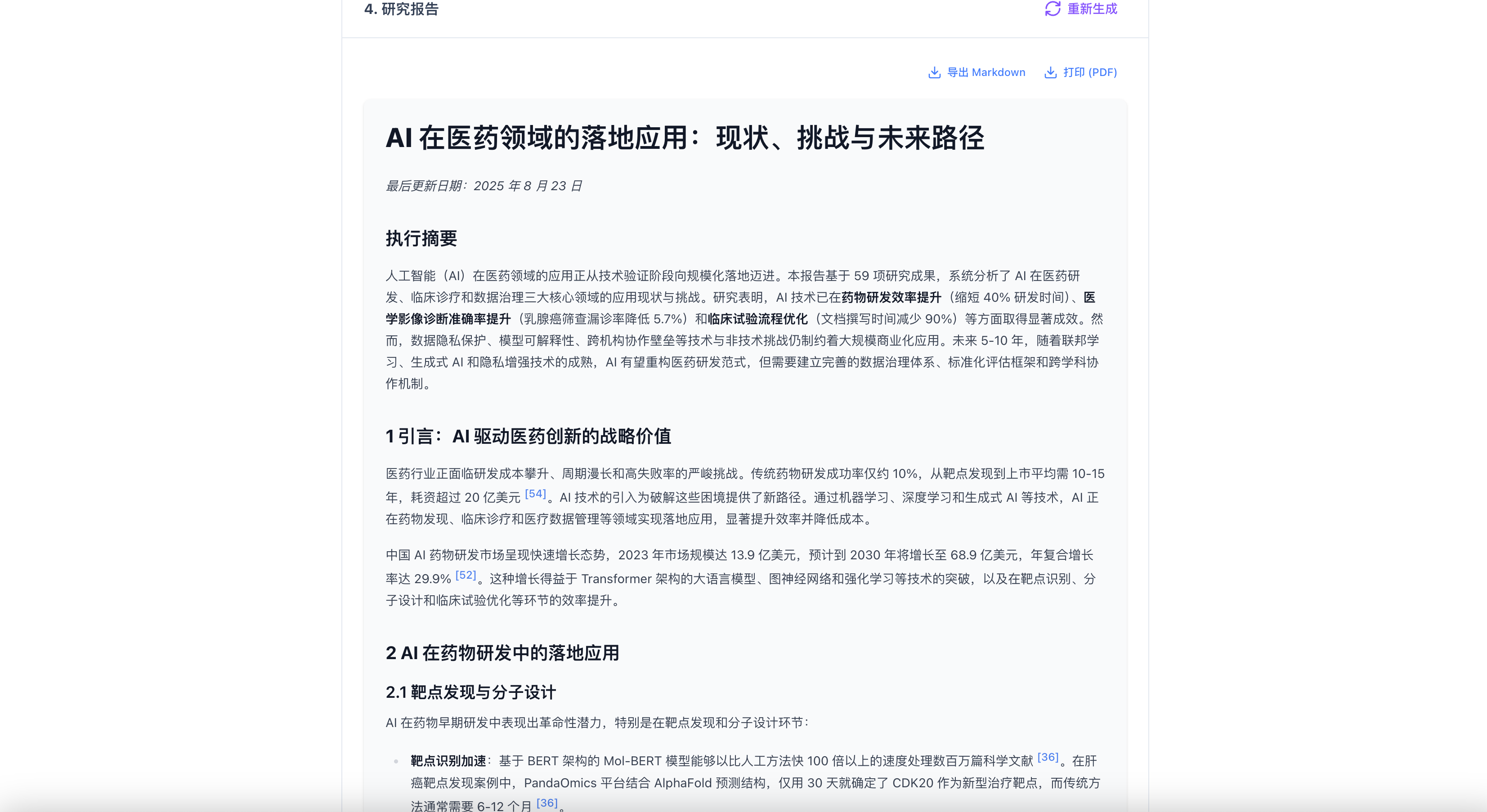
# 5. 参考资料
[1] 深度研究智能体(Deep Research Agent)全面综述:从技术架构到未来挑战 from 知乎 (opens new window)
[2] Deep Research Agents: A Systematic Examination And Roadmap from Arxiv (opens new window)
[3] Deep Research的全面综述:系统、方法与应用 from 知乎 (opens new window)
[4] Deep Research的原理与解析|附多个产品效果对比 from 知乎 (opens new window)
[5] Introducing deep research from OpenAI官网 (opens new window)
[6] DeepMind开源全栈「Deep Research」项目,AI 研究将人人可用 from 微信公众号 (opens new window)
[7] 开源版Deep Research!接入DeepSeek一键生成深度研究报告,可视化检索过程 from 知乎 (opens new window)